简介
之前在Aria2开源项目上强制改成项目想要的效果,在它原本的基础上实现了utp,nat打洞,udp ReusePORT,bt跟http多线程下载 最终导致项目不够稳定,结果就是项目还没上线就直接重写,现在重写了3个多月,已经大体实现,这里整理下 最新遇到的libuv与utp结合的问题
关于libuv的介绍,可以查看这个链接
https://github.com/libuv/libuv
libuv是一个支持多平台的异步IO库。它主要是为了node.js而开发的,但是也可以用于Luvit, Julia, pyuv及其他软件。
关于utp的介绍,可以查看这个链接
https://github.com/bittorrent/libutp
libutp其实是 bittorrent 开源出来的,utp本质还是udp,不过在udp的基础上,实现了类似utp的滑动窗口控制,mtu控制,rto,rrt,EACK等的特性使使用者用起来跟tcp一样,而不用考虑丢包,乱序的情况
libuv+utp结合使用的问题
1.由于调用libuv的uv_udp_send api发送udp数据的时候,内部并不会拷贝保存要发送的数据,所以对于发送方来说,外面一层一定要自己维护一个缓冲区,保证libuv将数据发送出去的时候,才能移除当前的数据要不然会导致访问了不合法的内存,导致闪退,而对于libutp来说,由于他要保证重发等机制,所以它会内部拷贝一份要发送的数据,方便自己管理控制,原本俩个库是没有什么问题的,但是结合起来就会有问题了,比如当前utp库在确认了这个包对方已经收到的时候,在执行释放的时候,由于不知道libuv不知道当前是否还有未发送的当前包,导致后续发送的时候,访问了非法的内存,导致闪退,下面有几种解决方案
每次发送拷贝一份
我们可以在utp库处理完数据调用sendto回调函数的时候,直接分配内存空间再拷贝一份数据再交给libuv发送,那么就不会存在发送不合法的数据问题,下面是本地的测试效果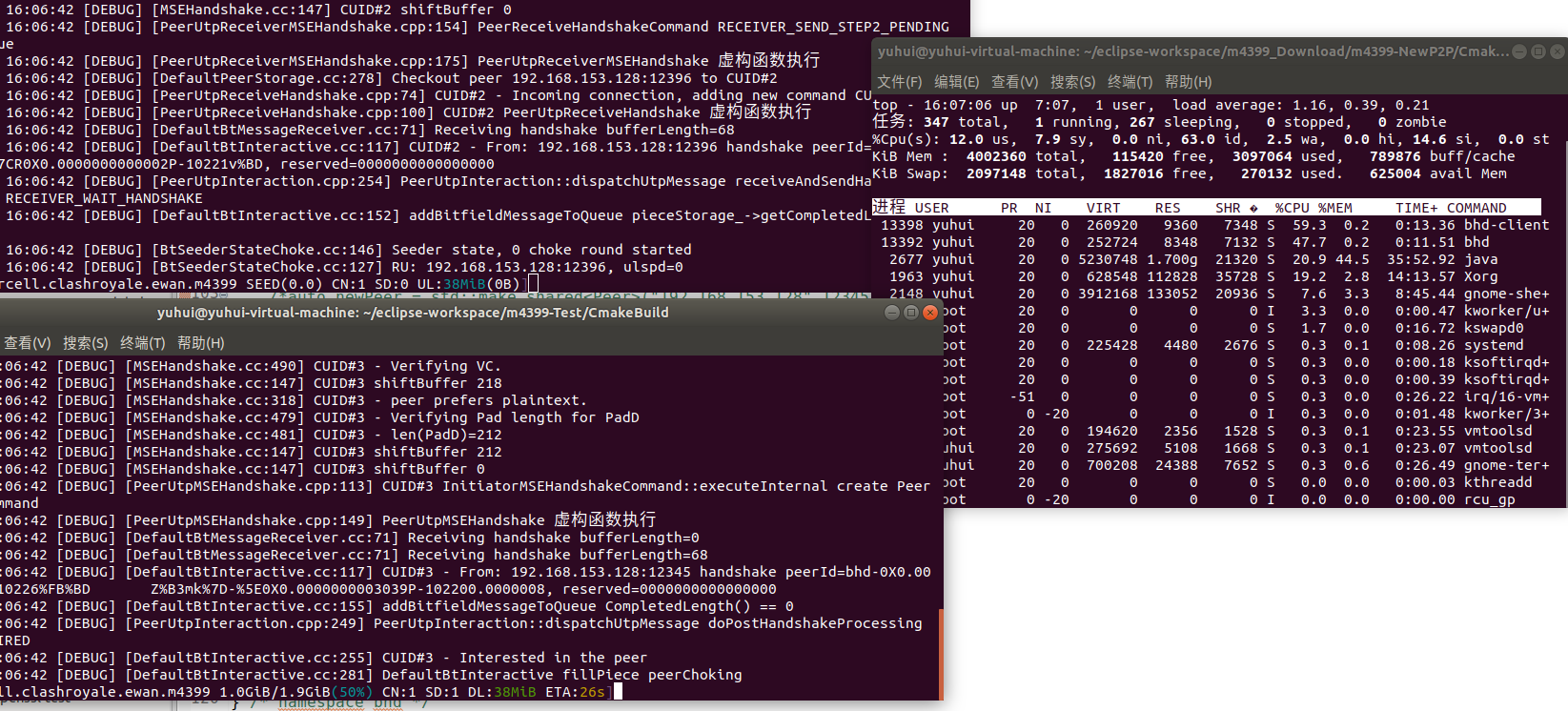
全拷贝函数简单实现
ssize_t UVSocketCore::utp_writeData(const char* data, int32_t len){
uv_buf_t buf;
buf.base = new char[len];
memcpy(buf.base,data,len);
buf.len = len;
uv_udp_send_t* udp_send = new uv_udp_send_t;
udp_send->data = buf.base;
//执行发送 For connected UDP handles, addr must be set to NULL, otherwise it will return UV_EISCONN error.
int32_t r = uv_udp_send(udp_send, udp_handle_, &buf, 1, nullptr,utp_on_send);
if (r) {
throw DL_ABORT_EX(fmt(EX_SOCKET_SEND, uv_strerror(r)));
}
return 0;
}
这只是在本地测试效果,是在不会丢包的情况下的表现,真实的网络情况下肯定会丢包的,那就会导致可能一个数据包一直丢包utp库一直重发,导致对于同一个数据包每次都执行了拷贝,这肯定是不合理的每次执行内存的分配,释放也是一个很影响效率的问题
直接使用同步的方式发送
如果数据经过libutp处理完之后,就直接将数据包发送出去,在utp库确认要删除这个数据包的时候,由于不会缓存数据包的情况,所以肯定不会有问题,下面是同步发送的效果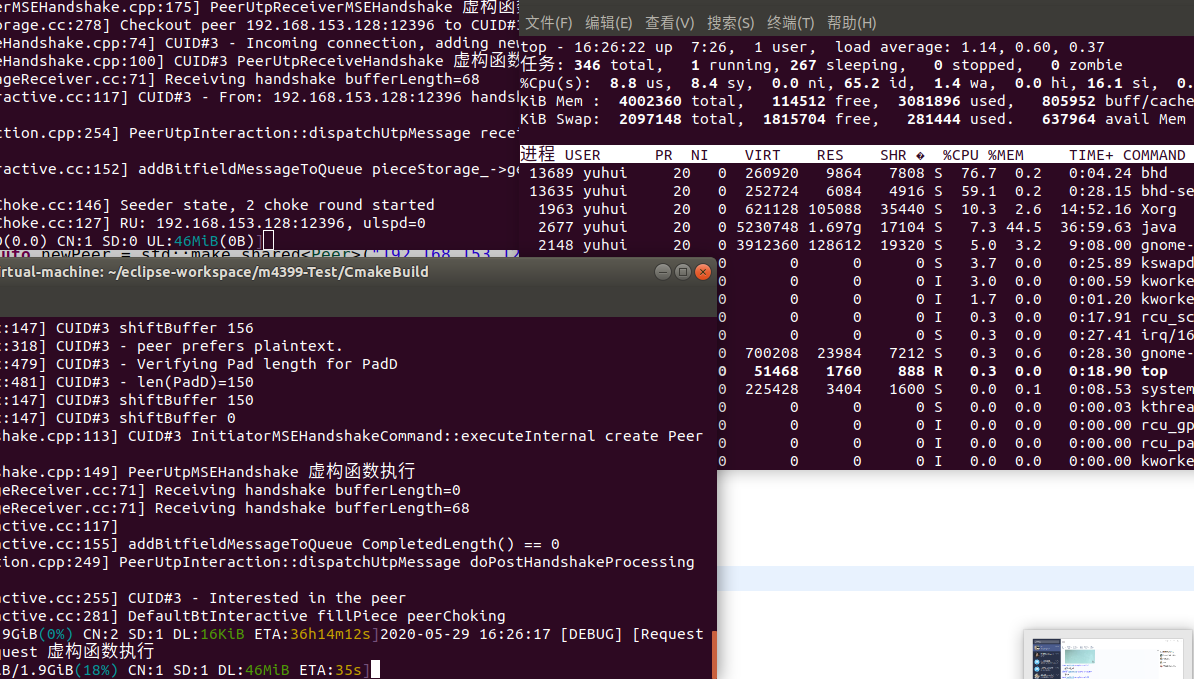
由于是采用直接同步发送的方式,所以并没有经过libuv库,直接调用write的方式,执行发送
ssize_t UVSocketCore::udpWriteData(const char* data,int32_t len){
enSureUdpHandle();
ssize_t r = -1;
int errNum = 0;
while ((r = write(udp_handle_->io_watcher.fd,data, len)) == -1 && A2_EINTR == SOCKET_ERRNO);
errNum = SOCKET_ERRNO;
if (r == -1 && A2_WOULDBLOCK(errNum)) { //为阻塞情况,
r = 0;
}
if (r == -1) {
//打印出现的问题
G_LOG_DEBUG(EX_SOCKET_SEND, errorMsg(errNum).c_str());
//抛出异常
throw DL_ABORT_EX(fmt(EX_SOCKET_SEND, errorMsg(errNum).c_str()));
}
return r;
}
可以看到同步发送的效果比全拷贝的效果还差,主要原因是前面一种虽然多执行了多次的拷贝,但是由于是经过libuv库,通过异步发送的方式,性能还是有点差距的,下面看看libuv是怎么样执行异步发送的
int uv__udp_send(uv_udp_send_t* req,
uv_udp_t* handle,
const uv_buf_t bufs[],
unsigned int nbufs,
const struct sockaddr* addr,
unsigned int addrlen,
uv_udp_send_cb send_cb) {
int err;
int empty_queue;
assert(nbufs > 0);
if (addr) {
err = uv__udp_maybe_deferred_bind(handle, addr->sa_family, 0);
if (err)
return err;
}
/* It's legal for send_queue_count > 0 even when the write_queue is empty;
* it means there are error-state requests in the write_completed_queue that
* will touch up send_queue_size/count later.
*/
empty_queue = (handle->send_queue_count == 0);
uv__req_init(handle->loop, req, UV_UDP_SEND);
assert(addrlen <= sizeof(req->addr));
if (addr == NULL)
req->addr.ss_family = AF_UNSPEC;
else
memcpy(&req->addr, addr, addrlen);
req->send_cb = send_cb;
req->handle = handle;
req->nbufs = nbufs;
req->is_utp = 0;
req->bufs = req->bufsml;
if (nbufs > ARRAY_SIZE(req->bufsml))
req->bufs = uv__malloc(nbufs * sizeof(bufs[0]));
if (req->bufs == NULL) {
uv__req_unregister(handle->loop, req);
return UV_ENOMEM;
}
memcpy(req->bufs, bufs, nbufs * sizeof(bufs[0]));
//更新当前handle要发送的数据队列大小,和当前要发送数据队列的长度
handle->send_queue_size += uv__count_bufs(req->bufs, req->nbufs);
handle->send_queue_count++;
//将当前构建的req添加到 handle的 write_queue 队列中
QUEUE_INSERT_TAIL(&handle->write_queue, &req->queue);
//激活当前的handle
uv__handle_start(handle);
//如果当前队列为空,并且当前没有正在处理完成队列,会直接发送数据
if (empty_queue && !(handle->flags & UV_HANDLE_UDP_PROCESSING)) {
uv__udp_sendmsg(handle);
/* `uv__udp_sendmsg` may not be able to do non-blocking write straight
* away. In such cases the `io_watcher` has to be queued for asynchronous
* write.
*/
if (!QUEUE_EMPTY(&handle->write_queue))
uv__io_start(handle->loop, &handle->io_watcher, POLLOUT);
} else {
uv__io_start(handle->loop, &handle->io_watcher, POLLOUT);
}
return 0;
}
//要监听的udp的io事件发生了变化
static void uv__udp_io(uv_loop_t* loop, uv__io_t* w, unsigned int revents) {
uv_udp_t* handle;
handle = container_of(w, uv_udp_t, io_watcher);
assert(handle->type == UV_UDP);
//如果当前的事件为数据到来,执行数据的接收
if (revents & POLLIN)
uv__udp_recvmsg(handle);
//如果当前的事件为写数据,执行写数据
if (revents & POLLOUT) {
//执行发送数据包
uv__udp_sendmsg(handle);
//处理已经发送的内容
uv__udp_run_completed(handle);
}
}
//处理已经发送的req
static void uv__udp_run_completed(uv_udp_t* handle) {
uv_udp_send_t* req;
QUEUE* q;
//标识当前正在处理结果的队列
assert(!(handle->flags & UV_HANDLE_UDP_PROCESSING));
handle->flags |= UV_HANDLE_UDP_PROCESSING;
while (!QUEUE_EMPTY(&handle->write_completed_queue)) {
q = QUEUE_HEAD(&handle->write_completed_queue);
//将当前元素从 队列中移除出去
QUEUE_REMOVE(q);
req = QUEUE_DATA(q, uv_udp_send_t, queue);
//从handle中移除当前的req
uv__req_unregister(handle->loop, req);
handle->send_queue_size -= uv__count_bufs(req->bufs, req->nbufs);
handle->send_queue_count--;
if (req->bufs != req->bufsml)
uv__free(req->bufs);
req->bufs = NULL;
if (req->send_cb == NULL)
continue;
if (req->status >= 0)
req->send_cb(req, 0);
else
req->send_cb(req, req->status);
}
//如果当前handle 要发送的数据队列为空,我们停止写事件的监听
if (QUEUE_EMPTY(&handle->write_queue)) {
/* Pending queue and completion queue empty, stop watcher. */
uv__io_stop(handle->loop, &handle->io_watcher, POLLOUT);
if (!uv__io_active(&handle->io_watcher, POLLIN))
uv__handle_stop(handle);
}
//重置当前没有正在处理完成队列
handle->flags &= ~UV_HANDLE_UDP_PROCESSING;
}
//使用udp发送数据
static void uv__udp_sendmsg(uv_udp_t* handle) {
uv_udp_send_t* req;
QUEUE* q;
struct msghdr h;
ssize_t size;
//一次就将当前handle的 write_queue 队列的内容,执行发送
while (!QUEUE_EMPTY(&handle->write_queue)) {
//获取到队列的首元素
q = QUEUE_HEAD(&handle->write_queue);
assert(q != NULL);
req = QUEUE_DATA(q, uv_udp_send_t, queue);
assert(req != NULL);
//往下走的就是都要发送的内容
memset(&h, 0, sizeof h);
if (req->addr.ss_family == AF_UNSPEC) {
h.msg_name = NULL;
h.msg_namelen = 0;
} else {
h.msg_name = &req->addr;
if (req->addr.ss_family == AF_INET6)
h.msg_namelen = sizeof(struct sockaddr_in6);
else if (req->addr.ss_family == AF_INET)
h.msg_namelen = sizeof(struct sockaddr_in);
else if (req->addr.ss_family == AF_UNIX)
h.msg_namelen = sizeof(struct sockaddr_un);
else {
assert(0 && "unsupported address family");
abort();
}
}
//要发送数据的赋值
h.msg_iov = (struct iovec*) req->bufs;
h.msg_iovlen = req->nbufs;
//执行发送
do {
size = sendmsg(handle->io_watcher.fd, &h, 0);
} while (size == -1 && errno == EINTR);
if (size == -1) {
//如果当前是写缓冲区满了,直接break掉,下次触发
if (errno == EAGAIN || errno == EWOULDBLOCK || errno == ENOBUFS){
//printf("uv__udp_sendmsg errno == EAGAIN || errno == EWOULDBLOCK || errno == ENOBUFS \n");
break;
}
}
req->status = (size == -1 ? UV__ERR(errno) : size);
//发送数据报是一项原子操作:要么所有数据被写或什么都不写(并且EMSGSIZE被引发)。那是为什么我们不处理部分写入。只是弹出请求从写队列移到完成队列,完成。
QUEUE_REMOVE(&req->queue);
QUEUE_INSERT_TAIL(&handle->write_completed_queue, &req->queue);
uv__io_feed(handle->loop, &handle->io_watcher);
}
}
首先是应用层调用发送函数,将要发送的内容封装到 uv_udp_send_t对象中,然后将当前对象做为一个节点的形式插入到 handle的write_queue队列中,如果当前队列没有内容,或者触发了POLLOUT可写的时候,会执行 uv__udp_sendmsg 发送函数,可以看到内部会通过遍历当前write_queue的元素,依次执行sendmsg函数,发送内容,当触发了errno == EAGAIN || errno == EWOULDBLOCK会中断当前的发送操作,那么剩余的内容就会下次再触发 POLLOUT事件的时候执行发送,还有这个UV_HANDLE_UDP_PROCESSING标识,这个可以做到在集中处理已经发送完的请求回调的时候,不允许直接发送数据,就算当前write_queue 为空,也不允许直接发送,所以这俩个操作,可以让udp的io做到集中发送的效果
utp确认要移除之前手动移除libuv对应的元素
当然你可以在libutp删除包的时候,遍历当前的发送队列中是否有当前要移除的数据包,如果有就从libuv 的写队列里面将他移除,但是在实现的时候发现了几个问题,首先,对于每个准备删除的包,都要从libuv 的 write_queue 队列中,遍历移除,虽然判断俩个元素是否相同可以直接通过比较指针是否一样来实现,但是通过阅读libutp源码的时候,发现对于ack,rst数据包,并没有提前分配内存,而是栈空间的内容
void UTPSocket::send_ack(bool synack) {
PacketFormatAckV1 pfa;
zeromem(&pfa);
size_t len;
last_rcv_win = get_rcv_window();
pfa.pf.set_version(1);
pfa.pf.set_type(ST_STATE);
pfa.pf.ext = 0;
pfa.pf.connid = conn_id_send;
pfa.pf.ack_nr = ack_nr;
pfa.pf.seq_nr = seq_nr;
pfa.pf.windowsize = (uint32) last_rcv_win;
len = sizeof(PacketFormatV1);
if (reorder_count != 0 && !got_fin_reached) {
assert(!synack);
pfa.pf.ext = 1;
pfa.ext_next = 0;
pfa.ext_len = 4;
uint m = 0;
assert(inbuf.get(ack_nr + 1) == NULL);
size_t window = min<size_t>(14 + 16, inbuf.size());
// Generate bit mask of segments received.
for (size_t i = 0; i < window; i++) {
if (inbuf.get(ack_nr + i + 2) != NULL) {
m |= 1 << i;
}
}
pfa.acks[0] = (byte) m;
pfa.acks[1] = (byte) (m >> 8);
pfa.acks[2] = (byte) (m >> 16);
pfa.acks[3] = (byte) (m >> 24);
len += 4 + 2;
}
send_data((byte *) &pfa, len, ack_overhead);
removeSocketFromAckList(this);
}
像对于这类的消息,比较指针是毫无意义的,而且由于是栈空间的内存,如果当前不直接发送,那么下次发送就好出现闪退了,libutp只有对data的数据包会暂存到自己的缓冲队列中 inbuf, outbuf中对于其他的数据包,直接执行发送,所以这种方案就直接抛弃了
最终优化方案
对于utp的data包会重发,所以我们可以在原本封装发送数据包的结构体,添加俩个字段send_count,以及is_need_delete ,send_count代表当前数据包发送的次数,我们在utp每次重发的时候,加一处理而在libuv里面当把数据包发送出去的时候,我们让send_count 减一处理,is_need_delete 代表当前数据包是否要删除的标识,所以当满足 is_need_delete && send_count==0的时候,就是代表可以安全释放的时候
//对于一个(将要)被发出去的包,有一个OutgoingPacket与其对应。
struct OutgoingPacket {
size_t length;// 总长
size_t payload;// 有效载荷
size_t send_count;//标识当前发送的次数
bool is_need_delete;//标识是否要移除
uint64 time_sent; // microseconds 当前数据包发送的时间
uint transmissions:31; // 总传输次数 ,后面的31代表使用31位
bool need_resend:1;//标识是否需要重新的发送,后面的1代表使用1个位来存储
byte data[1];//这里的data是个VLA,实际上是包头+数据包的全部内容。注意到最好不要将包头和数据包分开存放,不然又要多一次复制的开销。
};
对于outbuf的元素其实我们还可以优化,原本是对于要发送的内容,我们会先分配内存空间,然后确认可以删除后,我们执行释放操作,由于存在大量的数据包,一直new,delete操作,所以我们可以利用
循环队列做到内存的重用,并且考虑到后续包使用的时候,可能当前分配的大小不够,会再次触发重新分配的操作,我们直接就分配当前utp允许发送的最大长度,也即是1402个字节,由于考虑到mtu的存在
size_t packet_size = get_udp_mtu();
outbuf.ensure_size(seq_nr, cur_window_packets);
pkt = (OutgoingPacket*) outbuf.get(seq_nr);
//如果获取的pkt为空,或者当前还没有被对方确认可删除,那么就重新分配内存空间,否则我们直接重用这块内存
if (pkt == NULL || !is_outgoing_pcaket_send_finish(pkt)) {
//分配内存空间,注意,我们这里直接分配当前utp允许发送的最大长度,方便后续的重用
pkt = (OutgoingPacket*) malloc((sizeof(OutgoingPacket) - 1) + header_size + packet_size);
} else {
//printf("UTPSocket::write_outgoing_packet Reuse seq %u pkt length %d outbuf size %ld %u \n",(uint)temp->seq_nr,pkt->length,outbuf.size());
}
//是否发出去的数据包已经发送完成,也即是 发送libuv已经发送完,而且 对方已经确认过,才返回true
bool is_outgoing_pcaket_send_finish(OutgoingPacket *pkt){
return pkt->is_need_delete && pkt->send_count == 0;
}
这是循环队列的定义
struct SizableCircularBuffer {
// This is the mask. Since it's always a power of 2, adding 1 to this value will return the size.
//这是标识。由于它始终是2的幂,因此将该值加1将返回大小。
size_t mask;
// This is the elements that the circular buffer points to 是一个存储 void *类型的数组
void **elements;
//获取元素
void *get(size_t i) const {
assert(elements);
return elements ? elements[i & mask] : NULL;
}
//添加 元素 默认mask的大小为15, 通过i & mask 重新确定新的下标,下标的大小为 0 - 15范围
void put(size_t i, void *data) { assert(elements); elements[i&mask] = data; }
//grow需要提供item和index,两个变量可以分别理解为缓冲区中最旧的序号和最新的序号,其中item - index表示最老的未确认的ATPPacket的序号。
void grow(size_t item, size_t index);
//实查看调用情况可以发现item表示要插入的元素的编号,如seq_nr;而index表示当前队列中元素的个数,如cur_window_packets,这样队列就不会出现假溢出的现象
void ensure_size(size_t item, size_t index) {
if (index > mask) {
grow(item, index);
}
}
//返回当前缓冲区的大小
size_t size() { return mask + 1; }
};
队列扩充的方法
void SizableCircularBuffer::grow(size_t item, size_t index)
{
// Figure out the new size. 确保每次分配的大小为2的幂次方大小
size_t size = mask + 1;
do size *= 2; while (index >= size);
// Allocate the new buffer
void **buf = (void**)calloc(size, sizeof(void*));
size--;
// Copy elements from the old buffer to the new buffer
//grow需要提供item和index,两个变量可以分别理解为缓冲区中最旧的序号和最新的序号,其中item - index表示最老的未确认的ATPPacket的序号。
for (size_t i = 0; i <= mask; i++) {
buf[(item - index + i) & size] = get(item - index + i);
}
// Swap to the newly allocated buffer
mask = size;
//重新分配了之后,我们要释放之前的内存空间,重新指向新的内存空间
free(elements);
elements = buf;
}
当我们在确定当前数据包被对方收到的时候,我们让is_need_delete 为true
//标识当前数据包可以移除
pkt->is_need_delete = true;
//free(pkt);
当utp在发送完的时候,含有携带数据,也即是pkt,这里要让引用计数减一处理
utp_pkt_decrease(extra_data->pkt);
//让当前的pkt 引用计数减一处理
void utp_pkt_decrease(void *data){
OutgoingPacket *pkt = (OutgoingPacket*)(data);
assert(pkt->send_count > 0);
pkt->send_count -= 1;
}
还有一个inbuf队列,这个队列用于存放当前收到的乱序的包,跟tcp很相似,如果当前收到的包不是下一个接着要处理的包,就放到这个队列中,所以我们也可以优化内存的大量分配释放的操作,
我们可以使用IntgoingPacket结构体来。对于接收到一个乱序包的时候,用于封装接收的内容以及状态
struct IntgoingPacket{
size_t length;//当前接收到数据的长度
bool is_ack;//当前接收到的数据包舒服已经确认过
byte data[1]; //用于存放真正接收到的数据
};
//由于考虑到后面的内存重用,我们直接分配utp允许分配的最大长度
size_t packet_max_size = conn->get_udp_mtu();
//如果到了这里,说明这个包不是重复的包,我们确定下是否可以复用
//如果获取的pkt为空,或者当前还没有被对方确认可删除,那么就重新分配内存空间,否则我们直接重用这块内存
if (in_pkt == NULL || !in_pkt->is_ack) {
//分配内存空间,注意,我们这里直接分配当前utp允许发送的最大长度,方便后续的重用
in_pkt = (IntgoingPacket*) malloc((sizeof(IntgoingPacket) -1) + packet_max_size);
//printf("utp_process_incoming malloc IntgoingPacket seq %u \n",(uint)pk_seq_nr);
} else {
//printf("utp_process_incoming Reuse seq %u inbuf size %ld \n",(uint)in_pkt->seq_nr,conn->inbuf.size());
}
对于不是data包的优化,原本是分配在栈内存的,由于要保留libuv的异步发送操作,所以肯定要分配堆内存,由于这个ack也是大量的new,delete操作,我们也使用内存队列来重复利用内存
这里我们也定义一个数据结构方便来管理
//对于ack,rst 数据结构的封装
struct OutgoingAckPacket{
size_t length;// 当前要发送数据包的长度
uint16 *ack_buf_size;//为了方便libuv 操作 上层 ack队列中,未发送的元素个数
bool is_sended;//标识当前是否已经发送
byte data[1];//这里的data是个VLA,
};
//发送ack包
void UTPSocket::send_ack(bool synack)
{
//确保输出的队列含有足够的空间允许添加保存
ackbuf.ensure_size(ack_buf_seq, ack_buf_size);
//真正要发送数据包的长度
const size_t header_size = sizeof(PacketFormatAckV1);
OutgoingAckPacket* pkt = (OutgoingAckPacket* )ackbuf.get(ack_buf_seq);
//如果获取的pkt为空,或者当前还没有发送出去,则分配内存空间,如果获取的pkt不为空,并且已经发送出去,则重用这块内存
if(pkt == NULL || (pkt != NULL && !pkt->is_sended)){
pkt = (OutgoingAckPacket*) malloc(sizeof(OutgoingAckPacket) - 1 + header_size);
//printf("UTPSocket::send_ack malloc \n");
}else{
//printf("UTPSocket::send_ack Reuse ackBuf size %ld \n",ackbuf.size());
}
//重置data部分
PacketFormatAckV1* pfa = (PacketFormatAckV1*) pkt->data;
memset(pfa, 0, header_size);
//重置pkt部分
pkt->ack_buf_size = &ack_buf_size;
pkt->is_sended = false;
//添加data内容
size_t len;
last_rcv_win = get_rcv_window();
pfa->pf.set_version(1);
pfa->pf.set_type(ST_STATE);
//如果扩展字段为0,代表不适用扩展内容
pfa->pf.ext = 0;
//告知当前的连接的id,这个很重要
pfa->pf.connid = conn_id_send;
//发送当前的ack,跟序列号包
pfa->pf.ack_nr = ack_nr;
pfa->pf.seq_nr = seq_nr;
//告知对方,我们的滑动窗口大小
pfa->pf.windowsize = (uint32)last_rcv_win;
len = sizeof(PacketFormatV1);
// that are shutting down 我们永远不需要发送EACK 对于正在进行关闭的连接
if (reorder_count != 0 && !got_fin_reached) {
//如果重新排序计数> 0,代表乱序, 则发送EACK。如果重新排序计数应始终为0,对于synacks
assert(!synack);
//代表当前需要使用到扩展字段
pfa->pf.ext = 1;
pfa->ext_next = 0;
pfa->ext_len = 4;
uint m = 0;
//重新排序计数只能为非零 ,如果数据包ack_nr +1还没有 已收到
//IntgoingPacket *in_package = (IntgoingPacket*)inbuf.get(ack_nr + 1);
//assert(in_package == NULL || !in_package->is_ack);
//也即是最多发送30个ack过去
size_t window = min<size_t>(14+16, inbuf.size());
// Generate bit mask of segments received.
for (size_t i = 0; i < window; i++) {
IntgoingPacket * in_package = (IntgoingPacket*)inbuf.get(ack_nr + i + 2);
if (in_package != NULL && !in_package->is_ack) {
m |= 1 << i;
#if UTP_DEBUG_LOGGING
log(UTP_LOG_DEBUG, "EACK packet [%u]", ack_nr + i + 2);
#endif
}
}
pfa->acks[0] = (byte)m;
pfa->acks[1] = (byte)(m >> 8);
pfa->acks[2] = (byte)(m >> 16);
pfa->acks[3] = (byte)(m >> 24);
len += 4 + 2;
}
//当前真正要发送的长度
pkt->length = len;
//保存到ack发送队列中,标识下一个要发送的数据包序列号加一处理,标识发送队列含有一个元素没有发送
ackbuf.put(ack_buf_seq, pkt);
ack_buf_seq++;
ack_buf_size++;
//printf("UTPSocket::send_ack ack_buf_size %d ack_buf_seq %d \n",ack_buf_size,ack_buf_seq);
//如果是包含了EACK,则发送的长度为26个字节
send_data((byte*)pkt->data,(byte*)pkt,false, pkt->length, ack_overhead);
removeSocketFromAckList(this);
}
当libuv发送完ack包的时候,我们让 is_sended 置为 true,同时让这个ack的队列大小减一处理
//对于ack之类的包,我们要设置标识为已发送
utp_set_ack_pkt_send_finish(extra_data->pkt);
//设置ack对应的包以及发送,并且将ack队列的大小减一处理
void utp_set_ack_pkt_send_finish(void *data){
OutgoingAckPacket *ack = (OutgoingAckPacket*)(data);
ack->is_sended = true;
*ack->ack_buf_size = *ack->ack_buf_size -1;
}
这样我们就解决了所有的问题,甚至优化了libutp原本的不足,下面是结果,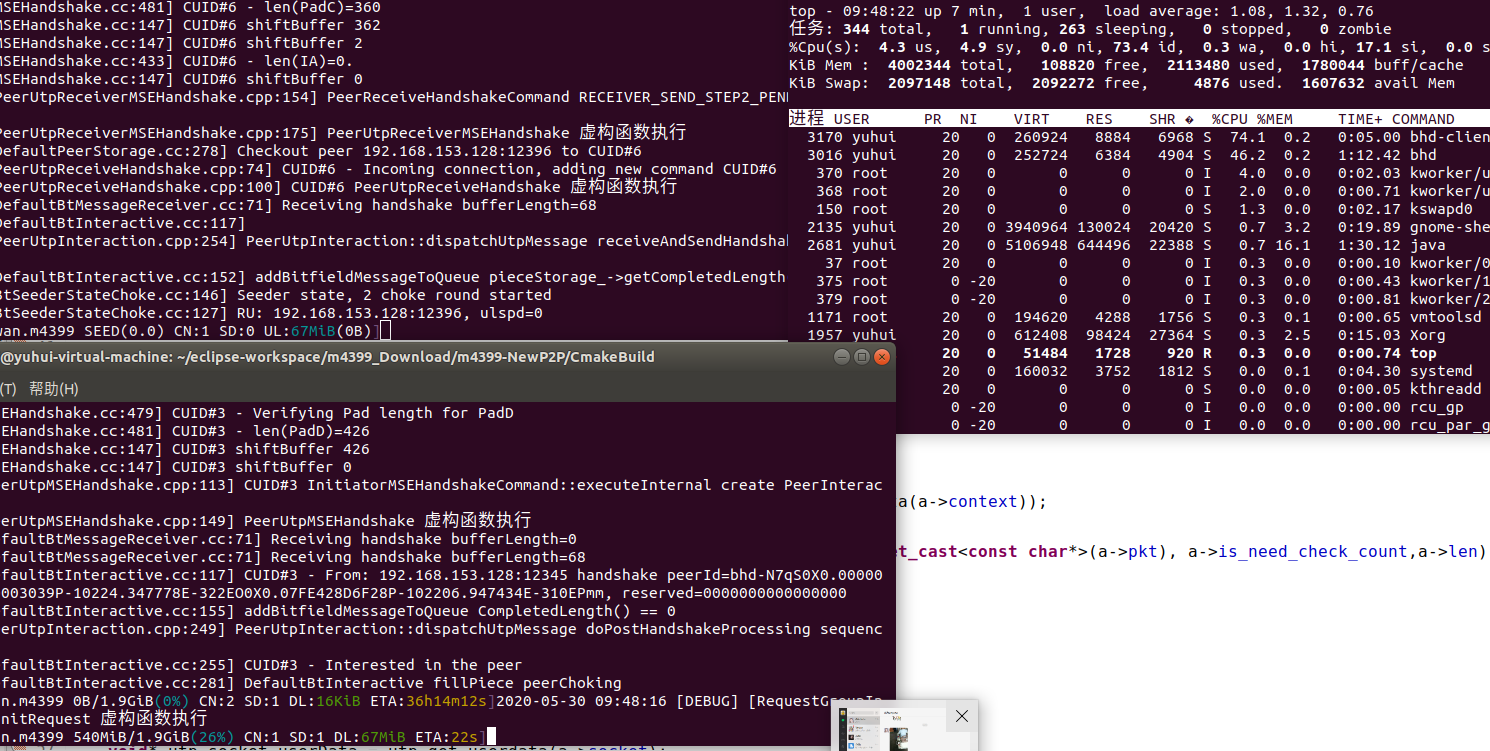
可以看出优化完对于服务端来说是影响比较大的,不管在cpu还是在上传速度方面都有很大的提升,但是对于客户端来说cpu的效果并没有多大的优化,我们利用perf来监控下对于客户端的性能主要消耗在哪里 我们可以执行 sudo perf record -g来监控cpu主要损耗的地方,当下载完的时候,按ctrl C退出检测,查看报告可以执行 perf report来查看报告,下面是报告的结果
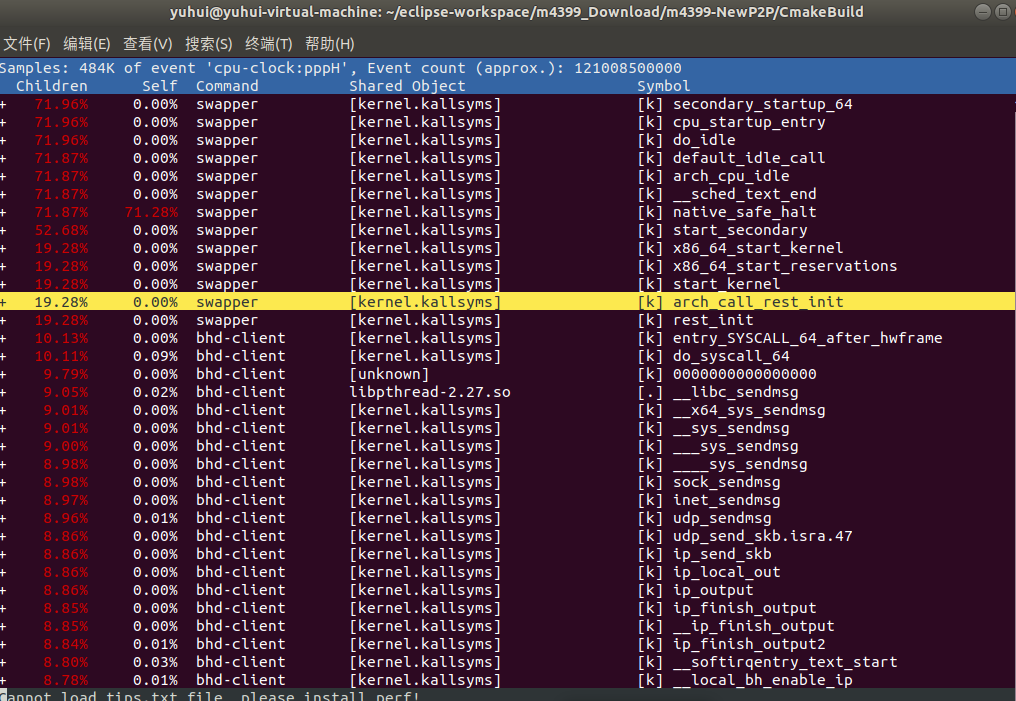
找到我们当前的进程,进行分析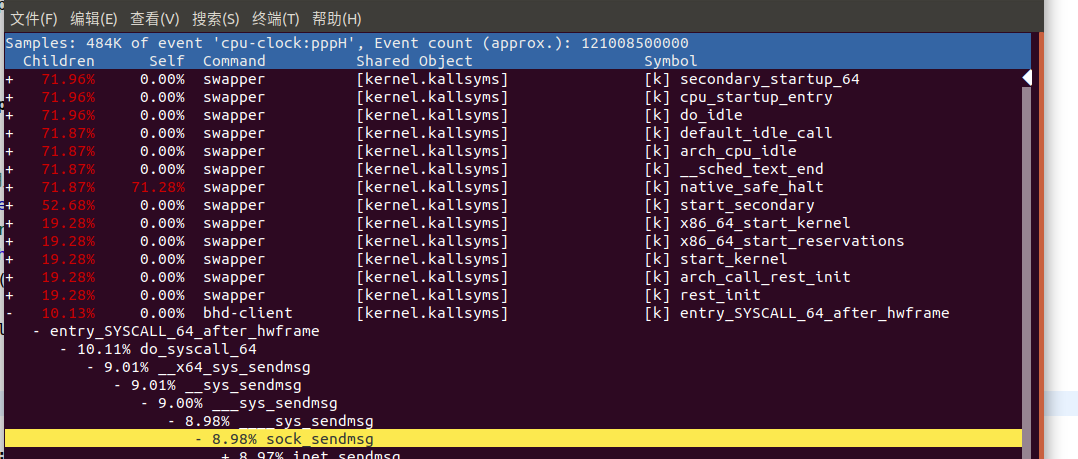
我们可以看到主要的损耗还是在发送的函数,还有为啥优化后服务端跟客户端的对比为啥差那么远,由于服务端是共享方,所以肯定会存在大量的发送数据到另一端,而客户端只是单纯的请求方,相比于服务端来说,发送的包或者内容肯定会少很多,其实对于客户端来说主要发送的还是确认包,也即是ack包,而且由于是本地传输,所以对于libuv的异步发送对于客户端来说表现的跟同步并没有多大的区别但是对于服务端来说,由于存在大量的发送数据包,即使在本地传输也会存在 io 集中处理的情况,所以会好很多,而且我们优化了 outbuf这个是针对发送的数据包用来存储的队列,由于客户端发送的data包很少,所以这个优化对于客户端来说,也并没有多大的影响,但是服务端存在大量的发送data包,所以服务端的优化就很明显了,还有我们有针对乱序的包优化的 inbuf,原本这个是针对客户端的主要优化,但是由于是本地传输,并不存在对包的情况,所以并不会有乱序包的情况,所以这个优化也没体现出来,但是在 真正的网络上效果肯定会有的,而且对于真正的下载来说很少存在只下载不共享的情况



