简介
最近俩个多月都在研究Aria2性能方面的问题,这里是Aria2的开源地址 https://github.com/aria2/aria2,
原本的Aria2是tcp的协议,我们在原本的基础上,添加了utp的支持,这里是utp的开源地址,https://github.com/bittorrent/libutp
也即是utorrent Bt下载软件开源出来的一种协议,本质是一种udp的协议,只是帮我们做了内部的处理,使我们使用起来跟tcp一样,下面分析下性能的情况
性能的表现
测试环境Ubuntu18.04 ,放在阿里云服务器上, 测试下载文件1.8G,测试方法模拟多个用户真实下载
测试我们之前移植utp到Aria2性能情况,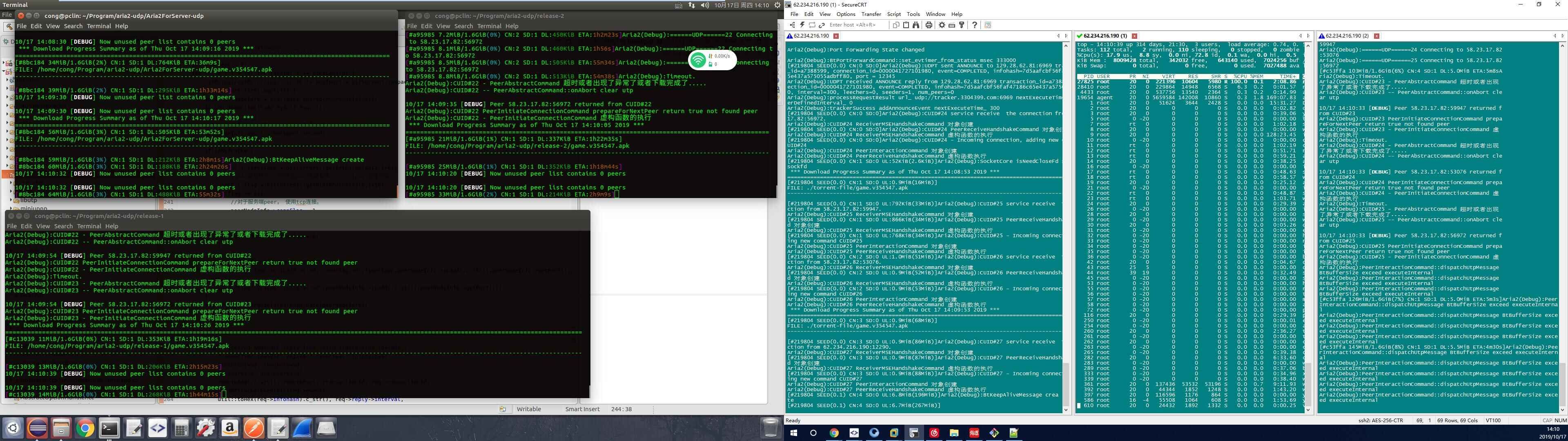
上面的情况是单线程utp的情况,可以看到utp的cpu几乎占满,接下来我们通过捉包分析差异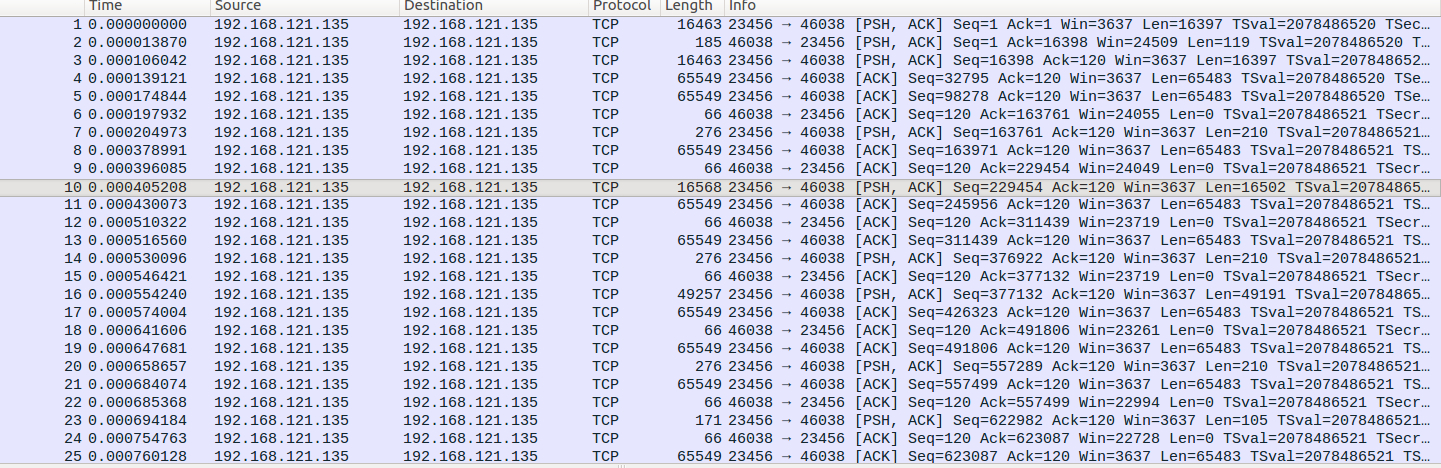
utp包的大小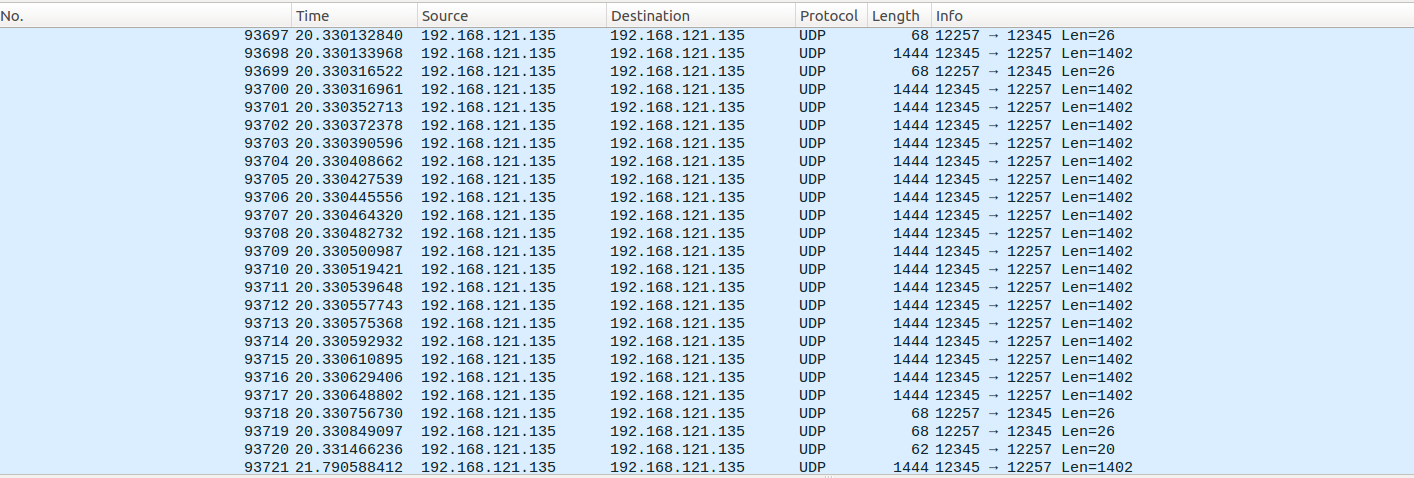
可以看到一个tcp包的大小为utp的64倍,加上utp为了tcp的逻辑实现的丢包重发的逻辑,通过测试下载同一个内容,utp发的包数量为tcp的200倍,通过捉包分析utorrent发包的数量比tcp的数量也为200倍,查看utorrent线程的数量既然达到了38个线程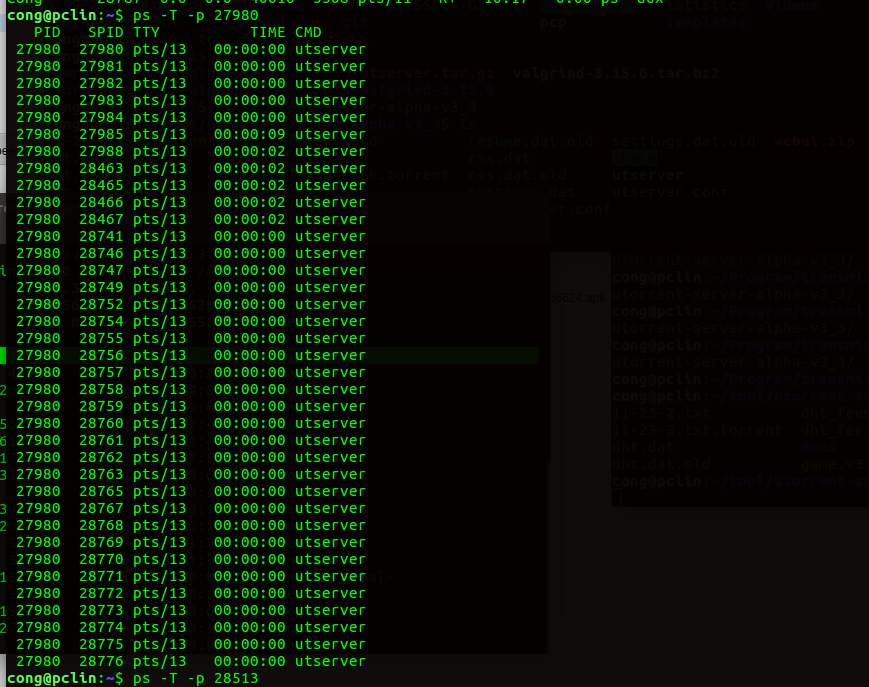
工具分析
首先使用pidstat 命令分析,可以看出用户态和内核态几乎各一半,当然还可以通过top,vmstat等工具来分析,甚至可以通过gcc增加-pg选项运行生成性能分析文件gmon.out.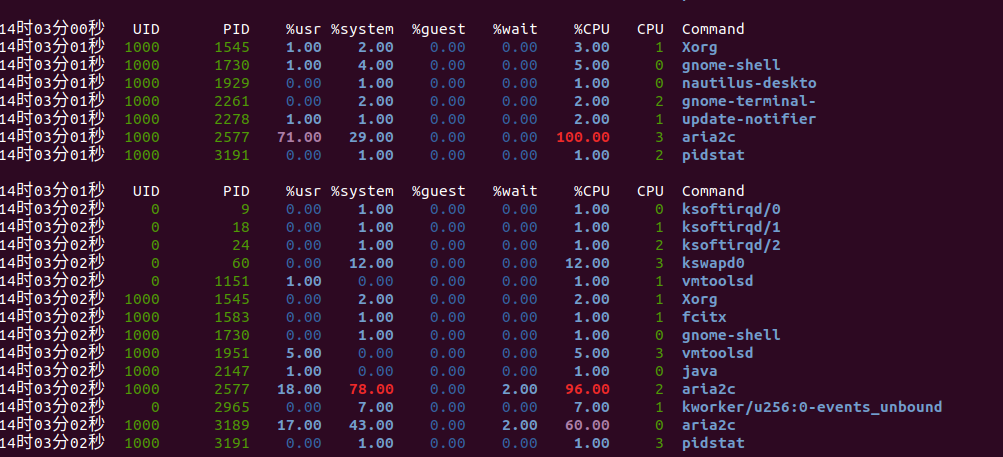
代码分析
首先看整体的框架
error_code::Value main(int argc, char** argv)
{
error_code::Value exitStatus = error_code::FINISHED;
if (context.reqinfo) {
exitStatus = context.reqinfo->execute();
}
return exitStatus;
}
error_code::Value MultiUrlRequestInfo::execute()
{
...
try {
e_->run();
}
catch (RecoverableException& e) {
A2_LOG_ERROR_EX(EX_EXCEPTION_CAUGHT, e);
}
...
return returnValue;
}
这里关键是这个run方法
//引擎开始运行 这边参数为true
int DownloadEngine::run(bool oneshot)
{
GlobalHaltRequestedFinalizer ghrf;
//如果 commands_ 或者 routineCommands_ 队列不为空,commands_一开始就有添加了一个保持事件响应的引用对象KeepRunningCommand 所以不为空
while (!commands_.empty() || !routineCommands_.empty()) {
//如果 commands_ 不为空,等待数据
if (!commands_.empty()) {
waitData();
}
noWait_ = false;
//重置时钟
global::wallclock().reset();
//计算下载的速度状态等,用来显示在输出控制台上
calculateStatistics();
//判断是否达到了刷新界面的时间,constexpr auto A2_DELTA_MILLIS = std::chrono::milliseconds(10);
if (lastRefresh_.difference(global::wallclock()) + A2_DELTA_MILLIS >= refreshInterval_) {
//刷新的间隔为1秒
refreshInterval_ = DEFAULT_REFRESH_INTERVAL;
//保存上一次刷新的时间
lastRefresh_ = global::wallclock();
//执行命令 ,状态为 Command::STATUS_ALL
executeCommand(commands_, Command::STATUS_ALL);
}
else {
//如果还没有到刷新的时间,执行命令,状态为 Command::STATUS_ACTIVE
executeCommand(commands_, Command::STATUS_ACTIVE);
}
//执行命令
executeCommand(routineCommands_, Command::STATUS_ALL);
afterEachIteration();
if (!noWait_ && oneshot) {
return 1;
}
}
//如果到了这里,就说明引擎已经开始停止
onEndOfRun();
return 0;
}
首先大概的讲解下Aria2的框架,Aria2是单线程模式,但是可以做到单cpu 时间片的效果, 内部通过执行一个一个的command来实现,其中有俩个command数组,一个是commands为普通的command,比如请求,下载类似的,还有一种为routineCommands 常规的command,也即是用来执行一些比较重要的command,比如进度保存的command等,而且每个command是有分状态的,这些状态的改变是通过epoll来改变的,Epoll通过监听对应的事件,来改变command的状态,然后决定是否要执行对应的command,当然常规的command是每次都要执行的
//引擎等待数据
void DownloadEngine::waitData()
{
struct timeval tv;
if (noWait_) {
tv.tv_sec = tv.tv_usec = 0;
}
else {
//求要等待的时间
auto t = std::chrono::duration_cast<std::chrono::microseconds>(refreshInterval_);
tv.tv_sec = t.count() / 1000000;
tv.tv_usec = t.count() % 1000000;
}
//调用具体类的实现
eventPoll_->poll(tv);
}
//tv是有超时时间的
void EpollEventPoll::poll(const struct timeval& tv)
{
// timeout is millisec
int timeout = tv.tv_sec * 1000 + tv.tv_usec / 1000;
int res;
//等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents表示每次能处理的最大事件数
while ((res = epoll_wait(epfd_, epEvents_.get(), EPOLL_EVENTS_MAX, timeout)) == -1 && errno == EINTR);
//如果有事件到来,处理这些事件
if (res > 0) {
for (int i = 0; i < res; ++i) {
KSocketEntry* p = reinterpret_cast<KSocketEntry*>(epEvents_[i].data.ptr);
p->processEvents(epEvents_[i].events);
}
}
else if (res == -1) {
int errNum = errno;
A2_LOG_INFO(
fmt("epoll_wait error: %s", util::safeStrerror(errNum).c_str()));
}
...
}
p->processEvents(epEvents_[i].events); 实现为
virtual void processEvents(int events)
{
if ((events_ & events) || ((EventPoll::IEV_ERROR | EventPoll::IEV_HUP) & events)) {
command_->setStatusActive();
}
if (EventPoll::IEV_READ & events) {//有数据到来
command_->readEventReceived();
}
if (EventPoll::IEV_WRITE & events) {//可以写缓冲区
command_->writeEventReceived();
}
if (EventPoll::IEV_ERROR & events) {
command_->errorEventReceived();
}
if (EventPoll::IEV_HUP & events) {
command_->hupEventReceived();
}
}
上面大体的思路是这样的,每次都会执行waitData来判断是否有数据到来,判断数据到来内部的实现是通过Epoll机制来实现的,这里EpollEventPoll 的逻辑是通过监听这些事件,实时的判断是否有数据的变更,如果有相应的事件到来,就改变command对应的状态,当然如果没有相应的事件到来,epoll是有设置超时时间的,所以当没有时间到来的时候,这个线程是可以休息的但是当有时间到来的时候,则会立刻的处理对应的事件,比如有数据到来当前command的状态就会变为 command_->setStatusActive();,接下来继续看
//判断是否达到了刷新界面的时间,constexpr auto A2_DELTA_MILLIS = std::chrono::milliseconds(10);
if (lastRefresh_.difference(global::wallclock()) + A2_DELTA_MILLIS >= refreshInterval_) {
//刷新的间隔为1秒
refreshInterval_ = DEFAULT_REFRESH_INTERVAL;
//保存上一次刷新的时间
lastRefresh_ = global::wallclock();
//执行命令 ,状态为 Command::STATUS_ALL
executeCommand(commands_, Command::STATUS_ALL);
}
else {
//如果还没有到刷新的时间,执行命令,状态为 Command::STATUS_ACTIVE
executeCommand(commands_, Command::STATUS_ACTIVE);
}
//执行命令
executeCommand(routineCommands_, Command::STATUS_ALL);
这里就是通过epoll将有数据到来改变状态的command分别处理,如果为STATUS_ACTIVE 状态的则立刻处理,否则要等一段时间才有机会执行
结果
这个框架采用单线程的方式来处理,内部通过epoll来处理,当没有数据到来则通过epoll设置的超时时间,来休眠当前的线程,如果有数据到来则立刻处理,再回到我们前面引进utp之后性能为什么会变的这么差,前面分析过utp发包的总量为tcp发包总量的200倍,也即是epoll触发有数据到会更多,从而cpu少了更多的休眠时间,导致这个while循环一直循环导致cpu很高,也即是说引进utp的程序,在网络不好的情况下,可以简单的类比为下面的情况
while(1){
….
}
而且由于是单线程的方式,当command的数量起来之后,cpu也是很吃力的,一个个command排队执行也是非常低效率的,下篇文章介绍怎么优化这个问题



