简介
前面分析了Matrix 中 IO Canary 模块,了解了对应的检测原理实现,本文继续分析 SQLite Lint 模块,在分析这块内容的时候最好知道对于SQLite Lint的性能主要检测的内容有哪些,这个可以参考这篇文章
https://mp.weixin.qq.com/s/laUgOmAcMiZIOfM2sWrQgw
文中介绍到他可以在我们开发,测试或者灰度阶段就可以发现隐藏的问题,既然要检测sql语句,那么就设计到了怎么收集App运行时的sql执行信息,包括执行语句、创建的表信息等。其中表相关信息可以通过 pragma 命令得到。对于执行语句,有两种情况
a)DB 框架提供了回调接口。比如微信使用的是 WCDB ,很容易就可以通过MMDataBase.setSQLiteTrace 注册回调拿到这些信息。
b)若使用 Android 默认的 DB 框架,SQLiteLint 提供了一种无侵入的获取到执行的sql语句及耗时等信息的方式。通过hook的技巧,向 SQLite3 C 层的 api sqlite3_profile 方法注册回调,
也能拿到分析所需的信息,从而无需开发者额外的打点统计代码。但是通过我阅读源码发现这个hook在7.0以上存在问题,源码的demo也并没有使用这种方式,而是通过一种通知的方式,也即是开发者将要检测的sql语句直接传递给SQLiteLint
对于检测的选项这里包括:
1.检测索引使用问题
2.检测冗余索引问题
3.检测 select * 问题
4.检测 Autoincrement 问题
5.检测建议使用 prepared statement
至于为什么要检测这些内容,具体可以查看上面的连接,文章中已经介绍的很清楚了,甚至包括了检测的标准
使用
在SQLite Lint页面中包含了下面的检测
源码分析
先看demo 的调用过程
public class MatrixApplication extends Application {
...
private static SQLiteLintConfig initSQLiteLintConfig() {
try {
return new SQLiteLintConfig(SQLiteLint.SqlExecutionCallbackMode.CUSTOM_NOTIFY);
} catch (Throwable t) {
return new SQLiteLintConfig(SQLiteLint.SqlExecutionCallbackMode.CUSTOM_NOTIFY);
}
}
@Override
public void onCreate() {
...
SQLiteLintConfig config = initSQLiteLintConfig();
SQLiteLintPlugin sqLiteLintPlugin = new SQLiteLintPlugin(config);
builder.plugin(sqLiteLintPlugin);
...
}
}
首先是执行了initSQLiteLintConfig ,构建了一个 SQLiteLintConfig对象,这里传递的模式为CUSTOM_NOTIFY,下面看看这俩个模式的选择,可以知道在7.0之后hook就会失败
/**
* The first step of SQLiteLint is to collect the executed sqls. SQL的检测,第一步就是收集Sql的信息
* Two way to achieve this.
*
* #HOOK: We will hook sqlite3_profile, and it will callback to our method when sqls are executed.
* @see com.tencent.sqlitelint.util.SQLite3ProfileHooker
* But hook will fail when tha android version is over Androd N. 但是在 Android N 以上 这个会失败
* TODO try to break through this limitation
*
* #CUSTOM_NOTIFY: It means that the user is responbisable to notify the sql execution. 通过通知的的方式来告知sql的执行
* @see #notifySqlExecution(String, String, int)
* TODO link example
*/
public enum SqlExecutionCallbackMode {
HOOK,
CUSTOM_NOTIFY,
}
//构建一个 SQLiteLintConfig 对象,这里传递进来的模式 CUSTOM_NOTIFY
public SQLiteLintConfig(SQLiteLint.SqlExecutionCallbackMode sqlExecutionCallbackMode) {
SQLiteLint.setSqlExecutionCallbackMode(sqlExecutionCallbackMode);
sConcernDbList = new ArrayList<>();
}
接着执行 SQLiteLint.setSqlExecutionCallbackMode(sqlExecutionCallbackMode);
public class SQLiteLint {
/**
* 首先执行 SqliteLint-lib so 的加载
*/
static {
SQLiteLintNativeBridge.loadLibrary();
}
private SQLiteLint() {
}
/**
* 当前所采用的的Sql的检测方式
*/
private static SqlExecutionCallbackMode sSqlExecutionCallbackMode = null;
public static void setSqlExecutionCallbackMode(SqlExecutionCallbackMode sqlExecutionCallbackMode) {
if (sSqlExecutionCallbackMode != null) {
return;
}
//赋值成员变量,标识当前所采用的模式
sSqlExecutionCallbackMode = sqlExecutionCallbackMode;
//如果为Hook方案
if (sSqlExecutionCallbackMode == SqlExecutionCallbackMode.HOOK) {
// hook must called before open the database
SQLite3ProfileHooker.hook();
}
}
...
}
在执行这个setSqlExecutionCallbackMode()函数之前,先看静态代码块的内容,执行了 SQLiteLintNativeBridge.loadLibrary();
public class SQLiteLintNativeBridge {
/**
* 加载so的操作
*/
public static void loadLibrary() {
System.loadLibrary("SqliteLint-lib");
SLog.nativeSetLogger(android.util.Log.VERBOSE);
}
...
}
可以看出首先调用了 System.loadLibrary("SqliteLint-lib"); 将 SqliteLint-lib 加载进来,这样就会调用的JNI_ONLoad函数的执行,具体的实现是在loader.cc 中
当调用System.loadLibrary 的时候就会调用这个方法
JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM *vm, void *reserved)
{
JNIEnv* env;
if (vm->GetEnv((void**) (&env), JNI_VERSION_1_6) != JNI_OK) {
sqlitelint::LOGE( "Initialize GetEnv null");
return -1;
}
//将 g_loaders 集合成员 中 init 为 true 的执行初始化的操作
vector<JNIModule>::iterator e = g_loaders->end();
for (vector<JNIModule>::iterator it = g_loaders->begin(); it != e; ++it)
{
//如果当前为初始化的时候,默认为 1的
if (it->init)
{
sqlitelint::LOGI( "Initialize module '%s'...", it->name);
//执行对应的函数指针
if (it->func(vm, env) != 0)
{
return -1;
}
}
}
return JNI_VERSION_1_6;
}
这里的g_loaders 的定义为
struct JNIModule
{
//注册的名称
const char *name;
//回调函数
ModuleInitializer func;
//是否初始化
bool init;
JNIModule(const char *name_, ModuleInitializer func_, bool init_)
: name(name_), func(func_), init(init_) {}
};
//全局的 g_loaders 集合
static vector<JNIModule> *g_loaders = nullptr;
可以看出 g_loaders 是一个全局的成员集合变量,用来存储JNIModule 的成员,JNIModule的定义就在上面,所以很好奇,难道g_loaders 在执行 JNI_OnLoad的时候就已经有内容了吗,如果有那么是怎么样
添加进来的呢,我们在 sqlite3_profile_hook.cc 中发现了有这样的内容,下面的内容看起来就像是 MODULE_INIT 执行初始化,MODULE_FINI用来执行销毁的操作
MODULE_INIT(sqlite3_proifle_hook){
kInitSuc = false;
kJvm = vm;
jint result = -1;
//找到 SQLiteLintUtil
jclass utilClass = env->FindClass("com/tencent/sqlitelint/util/SQLiteLintUtil");
if (utilClass == nullptr) {
return result;
}
//由于涉及到多线程,所以要变成GlobalRef
kUtilClass = reinterpret_cast<jclass>(env->NewGlobalRef(utilClass));
//找到 SQLiteLintUtil 中的 getThrowableStack 方法
kMethodIDGetThrowableStack = env->GetStaticMethodID(kUtilClass, "getThrowableStack", "()Ljava/lang/String;");
if (kMethodIDGetThrowableStack == nullptr) {
return result;
}
//标识初始化成功
kInitSuc = true;
return 0;
}
MODULE_FINI(sqlite3_proifle_hook) {
//释放全局的 引用
if (kUtilClass) {
env->DeleteGlobalRef(kUtilClass);
}
//重置变量
kInitSuc = false;
kStop = true;
return 0;
}
下面我们看看MODULE_INIT,MODULE_FINI的定义
#define MODULE_INIT(name) \
static int ModuleInit_##name(JavaVM *vm, JNIEnv *env); \
static void __attribute__((constructor)) MODULE_INIT_##name() \
{ \
register_module_func(#name, ModuleInit_##name, 1); \
} \
static int ModuleInit_##name(JavaVM *vm, JNIEnv *env)
#define MODULE_FINI(name) \
static int ModuleFini_##name(JavaVM *vm, JNIEnv *env); \
static void __attribute__((constructor)) MODULE_FINI_##name() \
{ \
register_module_func(#name, ModuleFini_##name, 0); \
} \
这里要注意这俩个宏有一个不同点就是调用register_module_func()第三个参数不一样,这个参数1代表为初始化的时候调用,0代表销毁的时候调用
static int ModuleFini_##name(JavaVM *vm, JNIEnv *env)
可以看出其实他们是一个宏,那么就很简单了,宏在c中只要直接展开就好了,比如我们展开一个内容少一点的 比如 MODULE_FINI(sqlite3_proifle_hook)函数,下面就是展开的内容
static int ModuleFini_sqlite3_proifle_hook(JavaVM *vm, JNIEnv *env);
//声明 __attribute__((constructor)) 会在 main函数执行之前被执行
static void __attribute__((constructor)) MODULE_FINI_sqlite3_proifle_hook()
{
register_module_func("sqlite3_proifle_hook", ModuleFini_sqlite3_proifle_hook, 0);
}
//定义
static int ModuleFini_sqlite3_proifle_hook(JavaVM *vm, JNIEnv *env)
{
if (kUtilClass) {
env->DeleteGlobalRef(kUtilClass);
}
kInitSuc = false;
kStop = true;
return 0;
}
展开之后就很简答了,一个是函数的声明,一个是函数的定义,唯一的这个要解释下
static void __attribute__((constructor)) MODULE_FINI_sqlite3_proifle_hook()
{
register_module_func("sqlite3_proifle_hook", ModuleFini_sqlite3_proifle_hook, 0);
}
这个其实是使用了 __attribute__中constructor和destructor,使用了之后,这个函数被设定为destructor属性,则该函数会在main()函数执行之后或者exit()被调用后被自动的执行
由于我们的为 __attribute__((constructor)) 所以会在main函数执行之前就会调用这个函数,所以会执行
register_module_func("sqlite3_proifle_hook", ModuleFini_sqlite3_proifle_hook, 0);
先看看 register_module_func()函数
SQLITELINT_EXPORT void register_module_func(const char *name, ModuleInitializer func, int init);
void register_module_func(const char *name, ModuleInitializer func, int init)
{
//如果为空,创建一个集合的对象,用来存储 JNIModule
if (!g_loaders)
g_loaders = new vector<JNIModule>();
//!!init 代表取反, 也即是为true 默认值
g_loaders->push_back(JNIModule(name, func, !!init));
}
而其中 ModuleInitializer其实为一个函数指针,下面是定义
typedef int (*ModuleInitializer)(JavaVM *vm, JNIEnv *env);
而我们的ModuleFini_sqlite3_proifle_hook()函数,刚好满足这个条件,那么到了这里就很简单了,当调用到
register_module_func("sqlite3_proifle_hook", ModuleFini_sqlite3_proifle_hook, 0); 对应到register_module_func(),将参数一一对应的化,name就为sqlite3_proifle_hook字符串
所以这里做的内容就是将这些传递过来的参数,构建成一个JNIModule,然后添加到了g_loaders全局变量中,那么对于MODULE_INIT(sqlite3_proifle_hook)也是类似的,只是这里调用
register_module_func()的时候,第三个参数为1,代表在初始化的时候执行,而MODULE_FINI()为在销毁的时候执行,下面我们看看这俩个参数的区别
再次回到JNI_OnLoad函数
//当调用System.loadLibrary 的时候就会调用这个方法
extern "C" JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM *vm, void *reserved)
{
JNIEnv* env;
if (vm->GetEnv((void**) (&env), JNI_VERSION_1_6) != JNI_OK) {
sqlitelint::LOGE( "Initialize GetEnv null");
return -1;
}
//将 g_loaders 集合成员 中 init 为 true 的执行初始化的操作
vector<JNIModule>::iterator e = g_loaders->end();
for (vector<JNIModule>::iterator it = g_loaders->begin(); it != e; ++it)
{
//如果当前为初始化的时候,默认为 1的
if (it->init)
{
sqlitelint::LOGI( "Initialize module '%s'...", it->name);
//执行对应的函数指针
if (it->func(vm, env) != 0)
{
return -1;
}
}
}
return JNI_VERSION_1_6;
}
在遍历g_loaders集合的时候,当it->init为真的时候就执行it->func(vm, env),前面已经说过JNIModule,这里的init对应的就为 0或者1, 当使用MODULE_INIT就为1,MODULE_FINI就为0,func为函数指针
所以可以做到在初始化的时候,就可以将所有注册的要初始化的函数都执行初始化,下面再看看销毁的时候调用过程
/**
* 当 so 销毁的时候,会回调这个函数,可以用来执行销毁的操作
*/
extern "C" JNIEXPORT void JNICALL JNI_OnUnload(JavaVM *vm, void *reserved)
{
JNIEnv* env;
if (vm->GetEnv((void**) (&env), JNI_VERSION_1_6) != JNI_OK) {
sqlitelint::LOGE( "Finalize GetEnv null");
return;
}
//相应的 将 g_loaders 集合 中的 成员中 init 为false 的,执行对应的函数指针,也即是销毁的操作
vector<JNIModule>::iterator e = g_loaders->end();
for (vector<JNIModule>::iterator it = g_loaders->begin(); it != e; ++it)
{
if (!it->init)
{
sqlitelint::LOGI("Finalize module '%s'...", it->name);
it->func(vm, env);
}
}
}
可以看到这里的调用过程跟JNI_Onload类似,唯一不同的就是 当满足了 if (!it->init)的时候才会调用 it->func(vm, env); 达到销毁的目的,至于为什么要这样写,估计这样写可以将对应模块的初始化
以及销毁的操作交给对应的模块来处理,就不会出现将所有的初始化,销毁操作都写在一个函数里面,比如我们刚刚看的是sqlite3_profile_hook.cc文件,其实这个文件的内容是没有作用的,以为我们并不是
采用hook的方式,在com_tencent_sqlitelint_SqliteLint.cc 中也有对应的MODULE_INIT,MODULE_FINI
MODULE_INIT(sqliteLint) {
kJvm = vm;
assert(env != nullptr);
//找到 SQLiteLintNativeBridge 类
jclass tmp_java_bridge_class = env->FindClass("com/tencent/sqlitelint/SQLiteLintNativeBridge");
if (tmp_java_bridge_class == nullptr) {
LOGE("MODULE_INIT tmpJavaBridgeClass is null");
return -1;
}
//变成全局变量
kJavaBridgeClass = reinterpret_cast<jclass>(env->NewGlobalRef(tmp_java_bridge_class));
...
}
在初始化的时候,找到java对应的类,和方法,属性等字段
MODULE_FINI(sqliteLint) {
if (kExecSqlObj)
env->DeleteLocalRef(kExecSqlObj);
if (kIssueClass)
env->DeleteGlobalRef(kIssueClass);
if (kJavaBridgeClass)
env->DeleteGlobalRef(kJavaBridgeClass);
return 0;
}
在销毁的释放,这些字段,在 com_tencent_sqlitelint_util_SLog.cc 中也有对应的MODULE_INIT,MODULE_FINI的使用,这个文件是Android日志文件,这里做了一层的中转输出,这里就不看了
这样JNI_OnLoad函数执行完毕,继续回调java层,在 TestSQLiteLintActivity 中有这样的使用
Plugin plugin = Matrix.with().getPluginByClass(SQLiteLintPlugin.class);
if (!plugin.isPluginStarted()) {
MatrixLog.i(TAG, "plugin-sqlite-lint start");
plugin.start();
}
public class SQLiteLintPlugin extends Plugin {
...
@Override
public void start() {
...
//设置报告的回调函数
SQLiteLint.setReportDelegate(new IssueReportBehaviour.IReportDelegate() {
@Override
public void report(SQLiteLintIssue issue) {
if (issue == null) {
return;
}
//提交报告
reportMatrixIssue(issue);
}
});
...
}
public void addConcernedDB(SQLiteLintConfig.ConcernDb concernDb) {
if (!isPluginStarted()) {
SLog.i(TAG, "addConcernedDB isPluginStarted not");
return;
}
if (concernDb == null) {
return;
}
mConfig.addConcernDB(concernDb);
//获取到当前要安装的数据库的路径
String concernedDbPath = concernDb.getInstallEnv().getConcernedDbPath();
//执行安装的操作
SQLiteLint.install(mContext, concernDb.getInstallEnv(), concernDb.getOptions());
//设置白名单
SQLiteLint.setWhiteList(concernedDbPath, concernDb.getWhiteListXmlResId());
//设置允许检查的内容
SQLiteLint.enableCheckers(concernedDbPath, concernDb.getEnableCheckerList());
}
...
}
接着看看测试点击按钮执行的逻辑
/**
* 开始数据库的创建测试
*/
private void startDBCreateTest() {
...
plugin.addConcernedDB(new SQLiteLintConfig.ConcernDb(TestDBHelper.get().getWritableDatabase()).enableAllCheckers());
}
首先调用TestDBHelper().get().getWritableDatabase()
public class TestDBHelper extends SQLiteOpenHelper {
...
//单例模式
public static TestDBHelper get() {
if (mHelper == null) {
synchronized (TestDBHelper.class) {
if (mHelper == null) {
mHelper = new TestDBHelper(MatrixApplication.getContext());
}
}
}
return mHelper;
}
public TestDBHelper(Context context) {
super(context, DB_NAME, null, DB_VERSION);
}
@Override
public void onCreate(SQLiteDatabase sqLiteDatabase) {
//创建表 testTable
String sql = "create table if not exists " + TABLE_NAME + " (Id integer primary key, name text, age integer)";
sqLiteDatabase.execSQL(sql);
...
}
@Override
public void onUpgrade(SQLiteDatabase sqLiteDatabase, int oldVersion, int newVersion) {
//升级的化,就直接删除表
String sql = "DROP TABLE IF EXISTS " + TABLE_NAME;
sqLiteDatabase.execSQL(sql);
String sql2 = "DROP TABLE IF EXISTS " + TABLE_NAME_AUTO_INCREMENT;
sqLiteDatabase.execSQL(sql2);
String sql3 = "DROP TABLE IF EXISTS " + TABLE_NAME_WITHOUT_ROWID_BETTER;
sqLiteDatabase.execSQL(sql3);
//表删除之后,重新的执行创建的过程
onCreate(sqLiteDatabase);
}
}
所以这边创建了一个TestDBHelper,本质是SQLiteOpenHelper,在onCreate的时候执行了创建表的操作,在升级的时候,删除表,又直接的创建数据库
接着执行 new SQLiteLintConfig.ConcernDb(),接着调用 enableAllCheckers()函数,下面看看这个函数的定义
public static final class ConcernDb {
//用于检测 索引的问题
private static final String EXPLAIN_QUERY_PLAN_CHECKER_NAME = "ExplainQueryPlanChecker";
//用于检测 Select * 的问题
private static final String AVOID_SELECT_ALL_CHECKER_NAME = "AvoidSelectAllChecker";
//用于检测 WithoutRow 的问题
private static final String WITHOUT_ROWID_BETTER_CHECKER_NAME = "WithoutRowIdBetterChecker";
//用于检测 AutoIncrement 的问题
private static final String AVOID_AUTO_INCREMENT_CHECKER_NAME = "AvoidAutoIncrementChecker";
//用于检测 PreparedStatement 的问题
private static final String PREPARED_STATEMENT_BETTER_CHECKER_NAME = "PreparedStatementBetterChecker";
//用于检测 冗余索引的问题
private static final String REDUNDANT_INDEX_CHECKER_NAME = "RedundantIndexChecker";
//数据库检查的安装环境
private final SQLiteLint.InstallEnv mInstallEnv;
//数据库检查的 配置
private final SQLiteLint.Options mOptions;
//数据库检测的白名单
private int mWhiteListXmlResId;
//当前允许数据库检测的 内容
private final List<String> mEnableCheckerList = new ArrayList<>();
public ConcernDb(SQLiteLint.InstallEnv installEnv, SQLiteLint.Options options) {
mInstallEnv = installEnv;
mOptions = options;
}
//ConcernDb 构造函数 传递一个可写的数据库进来
public ConcernDb(SQLiteDatabase db) {
assert db != null;
//构建一个 InstallEnv 的对象
mInstallEnv = new SQLiteLint.InstallEnv(db.getPath(), new SimpleSQLiteExecutionDelegate(db));
mOptions = SQLiteLint.Options.LAX;
}
/**
* 设置数据库检测的白名单
*/
public ConcernDb setWhiteListXml(final int xmlResId) {
mWhiteListXmlResId = xmlResId;
return this;
}
public SQLiteLint.InstallEnv getInstallEnv() {
return mInstallEnv;
}
public SQLiteLint.Options getOptions() {
return mOptions;
}
//获取到数据库检测的白名单
public int getWhiteListXmlResId() {
return mWhiteListXmlResId;
}
/**
* 执行check的检查,这里是检查所有的情况
* @return
*/
public ConcernDb enableAllCheckers() {
return enableExplainQueryPlanChecker()
.enableAvoidSelectAllChecker()
.enableWithoutRowIdBetterChecker()
.enableAvoidAutoIncrementChecker()
.enablePreparedStatementBetterChecker()
.enableRedundantIndexChecker();
}
...
}
首先在构造函数 中 执行 mInstallEnv = new SQLiteLint.InstallEnv(db.getPath(), new SimpleSQLiteExecutionDelegate(db));
首先将 传递过来的数据库db 传递到了 SimpleSQLiteExecutionDelegate,这个类是更像是一个代理的实现,用来真正的执行数据库的操作,这个会由JNI层来触发
public final class SimpleSQLiteExecutionDelegate implements ISQLiteExecutionDelegate {
private static final String TAG = "SQLiteLint.SimpleSQLiteExecutionDelegate";
private final SQLiteDatabase mDb;
public SimpleSQLiteExecutionDelegate(SQLiteDatabase db) {
assert db != null;
mDb = db;
}
/**
* 执行查询的操作
* @param selection
* @param selectionArgs
* @return
* @throws SQLException
*/
@Override
public Cursor rawQuery(String selection, String... selectionArgs) throws SQLException {
if (!mDb.isOpen()) {
SLog.w(TAG, "rawQuery db close");
return null;
}
//最终调用了 SQLiteDatabase rawQuery 来执行查询
return mDb.rawQuery(selection, selectionArgs);
}
@Override
public void execSQL(String sql) throws SQLException {
if (!mDb.isOpen()) {
SLog.w(TAG, "rawQuery db close");
return;
}
mDb.execSQL(sql);
}
}
接着构建一个InstallEnv 对象,保存了传递过来的内容
/**
* A data struct of some variables which guide the installation and make SQLiteLint work.
* 一些变量的数据结构,指导安装并使SQLiteLint工作。
* Used in {@link #install(Context, InstallEnv, Options)}
*/
public static final class InstallEnv {
//要检查的数据库的路径
private final String mConcernedDbPath;
//数据库执行的委托
private final ISQLiteExecutionDelegate mSQLiteExecutionDelegate;
/**
* @param concernedDbPath the path of the database which will be observed and checked
* @param executionDelegate SQLiteLint will do some sql execution use SQLite, but SQLiteLint will delegate the execution.
* A simple delegate like {@link SimpleSQLiteExecutionDelegate}
*/
public InstallEnv(String concernedDbPath, ISQLiteExecutionDelegate executionDelegate) {
assert concernedDbPath != null;
assert executionDelegate != null;
mConcernedDbPath = concernedDbPath;
mSQLiteExecutionDelegate = executionDelegate;
}
...
}
接着调用 enableAllCheckers()函数,回到前面ConcernDb类的定义,其实这里既是配置要检测的内容,比如ExplainQueryPlanChecker 代表检查索引,AvoidSelectAllChecker代表检查selec*
所以配置检查所有的内容,最终要检查的内容 都是添加到了 mEnableCheckerList 字符串的集合中,后面要传递给JNI层告知当前要检查的种类,接着调用addConcernedDB函数
/**
* 添加concernDb
* @param concernDb
*/
public void addConcernedDB(SQLiteLintConfig.ConcernDb concernDb) {
if (!isPluginStarted()) {
SLog.i(TAG, "addConcernedDB isPluginStarted not");
return;
}
if (concernDb == null) {
return;
}
mConfig.addConcernDB(concernDb);
//获取到当前要安装的数据库的路径
String concernedDbPath = concernDb.getInstallEnv().getConcernedDbPath();
//执行安装的操作
SQLiteLint.install(mContext, concernDb.getInstallEnv(), concernDb.getOptions());
//设置白名单
SQLiteLint.setWhiteList(concernedDbPath, concernDb.getWhiteListXmlResId());
//设置允许检查的内容
SQLiteLint.enableCheckers(concernedDbPath, concernDb.getEnableCheckerList());
}
之后执行 SQLiteLint.install(mContext, concernDb.getInstallEnv(), concernDb.getOptions());
public static void install(Context context, InstallEnv installEnv, Options options) {
...
options = (options == null) ? Options.LAX : options;
//执行安装的操作
SQLiteLintAndroidCoreManager.INSTANCE.install(context, installEnv, options);
}
public enum SQLiteLintAndroidCoreManager {
//单例 ,使用枚举创建单例
INSTANCE;
private static final String TAG = "SQLiteLint.SQLiteLintAndroidCoreManager";
/**
* key: the concerned db path 要检测的数据库的路径
* value: a SQLiteLintAndroidCore to check this db
*/
private ConcurrentHashMap<String, SQLiteLintAndroidCore> mCoresMap = new ConcurrentHashMap<>();
/**
* 执行安装的操作
* @param context
* @param installEnv
* @param options
*/
public void install(Context context, SQLiteLint.InstallEnv installEnv, SQLiteLint.Options options) {
//获取到当前要检查的数据库的路径
String concernedDbPath = installEnv.getConcernedDbPath();
//如果已经存在集合中,忽略
if (mCoresMap.containsKey(concernedDbPath)) {
SLog.w(TAG, "install twice!! ignore");
return;
}
//构建一个 SQLiteLintAndroidCore 对象,然后添加到集合 mCoresMap 中
SQLiteLintAndroidCore core = new SQLiteLintAndroidCore(context, installEnv, options);
mCoresMap.put(concernedDbPath, core);
}
...
}
可以看出这是一个使用枚举的单例写法,接着会构建一个 SQLiteLintAndroidCore 对象
SQLiteLintAndroidCore(Context context, SQLiteLint.InstallEnv installEnv, SQLiteLint.Options options) {
mContext = context;
//初始化 ,创建SqliteOpenHelper
SQLiteLintDbHelper.INSTANCE.initialize(context);
//获取到当前要检测的数据库的路径
mConcernedDbPath = installEnv.getConcernedDbPath();
//获取到数据库执行的委托对象
mSQLiteExecutionDelegate = installEnv.getSQLiteExecutionDelegate();
//如果当前的数据库的检测模式为 Hook
if (SQLiteLint.getSqlExecutionCallbackMode() == SQLiteLint.SqlExecutionCallbackMode.HOOK) {
//执行hook操作
SQLite3ProfileHooker.hook();
}
//native 层的安装
SQLiteLintNativeBridge.nativeInstall(mConcernedDbPath);
//构建一个 mBehaviors 集合 ,添加一个 PersistenceBehaviour 成员
mBehaviors = new ArrayList<>();
/*PersistenceBehaviour is a default pre-behaviour */
mBehaviors.add(new PersistenceBehaviour());
//默认为 BEHAVIOUR_ALERT ,再往 mBehaviors 中添加一个 IssueAlertBehaviour 对象
if (options.isAlertBehaviourEnable()) {
mBehaviors.add(new IssueAlertBehaviour(context, mConcernedDbPath));
}
if (options.isReportBehaviourEnable()) {
mBehaviors.add(new IssueReportBehaviour(SQLiteLint.sReportDelegate));
}
}
首先调用 SQLiteLintDbHelper.INSTANCE.initialize(context);
public enum SQLiteLintDbHelper {
//使用枚举 构建单例
INSTANCE;
...
//单例 ,是一个 SQLiteOpenHelper 对象
private volatile InternalDbHelper mHelper;
public SQLiteDatabase getDatabase() {
if (mHelper == null) {
throw new IllegalStateException("getIssueStorage db not ready");
}
return mHelper.getWritableDatabase();
}
public void initialize(Context context) {
if (mHelper == null) {
synchronized (this) {
if (mHelper == null) {
mHelper = new InternalDbHelper(context);
}
}
}
}
private static final class InternalDbHelper extends SQLiteOpenHelper {
//要打开的数据库名, SQLiteLintInternal.db 是一个用来保存Issure 的数据库
private static final String DB_NAME = "SQLiteLintInternal.db";
private static final int VERSION_1 = 1;
InternalDbHelper(Context context) {
super(context, DB_NAME, null, VERSION_1);
}
@Override
public void onCreate(SQLiteDatabase db) {
SLog.i(TAG, "onCreate");
//执行创建数据库
db.execSQL(IssueStorage.DB_VERSION_1_CREATE_SQL);
//创建索引
for (int i = 0; i < IssueStorage.DB_VERSION_1_CREATE_INDEX.length; i++) {
db.execSQL(IssueStorage.DB_VERSION_1_CREATE_INDEX[i]);
}
}
@Override
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
}
}
}
可以看出这也是一个单例,其实这个是内部的数据库,用来存储分析的结果,也即是当分析到了结果,会先经过这个数据库进行保存,继续往下面执行由于我们当前的模式不为hook方式,所以不会执行
SQLite3ProfileHooker.hook();接着就会执行到 SQLiteLintNativeBridge.nativeInstall(mConcernedDbPath); 这是一个native 方法,对应的jni方法的实现为
/**
* 执行native层的安装操作
* @param env
* @param name
*/
void Java_com_tencent_sqlitelint_SQLiteLintNativeBridge_nativeInstall(JNIEnv *env, jobject, jstring name) {
//当前要检测的 数据库的路径
char *filename = jstringToChars(env,name);
//安装 SQLiteLint ,OnIssuePublish 为函数指针,用于进一步的将结果传回java层
InstallSQLiteLint(filename, OnIssuePublish);
//释放操作
free(filename);
//传递SQL 执行的函数指针
SetSqlExecutionDelegate(SqliteLintExecSql);
}
执行 InstallSQLiteLint(filename, OnIssuePublish);
//执行安装的操作 ,issue_callback 为 传递结果的函数指针
void InstallSQLiteLint(const char* db_path, OnPublishIssueCallback issue_callback) {
LintManager::Get()->Install(db_path, issue_callback);
}
这里LintManager其实为一个单例
// A singleton and it manage the lint
class LintManager {
public :
static LintManager* Get();
...
private:
//单例模式,构造函数为 私有
LintManager(){};
~LintManager(){};
private:
...
//单例模式
static LintManager *instance_;
};
//获取到 LintManager 对象,如果是第一次调用,执行创建
LintManager* LintManager::Get() {
if (!instance_){
//加锁操作
std::unique_lock<std::mutex> lock(lints_mutex_);
if (!instance_){
instance_ = new LintManager();
}
//解锁 操作
lock.unlock();
}
return instance_;
}
当第一次调用的时候就会创建一个LintManager 对象,之后都不会进行创建了,接着调用 Install函数
/**
* 执行安装的操作
* @param db_path
* @param issued_callback
*/
void LintManager::Install(const char* db_path, OnPublishIssueCallback issued_callback) {
sInfo("LintManager::Install dbPath:%s", db_path);
//加锁
std::unique_lock<std::mutex> lock(lints_mutex_);
//如果 lints_ 集合中 以及存在 db_path ,直接返回
std::map<const std::string, Lint*>::iterator it = lints_.find(db_path);
if (it != lints_.end()) {
//已经在 集合中存在,解锁
lock.unlock();
sWarn("Install already installed; dbPath: %s", db_path);
return;
}
//如果到了这里说明不存在,构建一个
Lint* lint = new Lint(db_path, issued_callback);
lints_.insert(std::pair<const std::string, Lint*>(db_path, lint));
//解锁
lock.unlock();
}
其中 lints_ 为 LintManager 中的一个集合,用来存储当前已经添加的检测 定义为
std::map<const std::string, Lint*> lints_;
集合的key为当前要添加检测的数据库的路径,这里的逻辑就是先检测当前的数据库路径是否已经添加过,如果已经添加过,直接返回,假设没有,就构建一个Lint 对象,然后存储到集合中
Lint::Lint(const char* db_path, OnPublishIssueCallback issued_callback)
: env_(db_path), checked_sql_cache_(500)//env_(db_path) 会调用 LintEnv(path)的构造函数,构建这样的对象,checked_sql_cache_ 集合的大小为500
, issued_callback_(issued_callback), exit_(false){
//构建一个线程, 线程执行的时候会执行 Check 函数
check_thread_ = new std::thread(&Lint::Check, this);
}
这里要注意在构建这个Lint 对象的时候传递的OnPublishIssueCallback 为函数指针,这个函数指针是用来中转结果的,跟上一篇的检测Io一样,将结果做一个中转,最后转到java层
这里的env_ 为 Lint 的一个成员变量 LintEnv env_;,这里执行 env_(db_path)就会调用对应的构造函数,LintEnv 这个对象用来代表这个数据库检测的环境
// LintEnv 构造函数的执行
LintEnv::LintEnv(std::string db_path) : db_path_(db_path), checked_sql_cnt_(0) {
int pos = db_path.find_last_of('/');
if (pos >= 0) {
db_file_name_ = db_path.substr(pos + 1);
} else {
db_file_name_ = db_path;
}
}
同时将 issued_callback 保存到 成员变量issued_callback_中,用于后面检测结果的中转,同时参加了一个线程check_thread_,线程执行的时候会执行&Lint::Check 函数
/**
* 在 check_thread_ 线程中 执行
*/
void Lint::Check() {
//这边又构建一个 init_check_thread_ 的线程,线程执行的时候,会执行 InitCheck 函数
init_check_thread_ = new std::thread(&Lint::InitCheck, this);
//用来存储要分发结果的集合
std::vector<Issue>* published_issues = new std::vector<Issue>;
std::unique_ptr<SqlInfo> sql_info;
SqlInfo simple_sql_info;
//这下面一般是检查是否有结果,有就分发出去之类的
while (true) {
//从queue 结果队列中 获取到内容,如果 队列中有元素,取出对头的元素,然后辅助给 sql_info ,如果没有元素,则会阻塞在这里
int ret = TakeSqlInfo(sql_info);
if (ret != 0) {
sError("check exit");
break;
}
...
}
}
可以看到当这个子线程执行的时候,又会创建另一个子线程 init_check_thread_ ,函数指针为Lint::InitCheck,这里先不去看这个函数的实现,继续回到nativeInstall 函数
void Java_com_tencent_sqlitelint_SQLiteLintNativeBridge_nativeInstall(JNIEnv *env, jobject, jstring name) {
//当前要检测的 数据库的路径
char *filename = jstringToChars(env,name);
//安装 SQLiteLint ,OnIssuePublish 为函数指针,用于进一步的将结果传回java层
InstallSQLiteLint(filename, OnIssuePublish);
//释放操作
free(filename);
//传递SQL 执行的函数指针
SetSqlExecutionDelegate(SqliteLintExecSql);
}
//传递全局的SQL 执行的函数指针
void SetSqlExecutionDelegate(SqlExecutionDelegate func){
kSqlExecutionDelegate = func;
}
这里的SqliteLintExecSql 也为函数指针,也是一个中转函数的,这个函数主要完成的操作当JNI层要操作数据库的时候,会通过这个函数,中转到Java层,其实真正的查询有java来操作
继续回到 java层的 addConcernedDB()函数,继续往下面执行
//设置白名单
SQLiteLint.setWhiteList(concernedDbPath, concernDb.getWhiteListXmlResId());
public static void setWhiteList(String concernedDbPath, final int xmlResId) {
//如果 INSTANCE 中 存在 concernedDbPath 路径 对应的 SQLiteLintAndroidCore 对象
if (SQLiteLintAndroidCoreManager.INSTANCE.get(concernedDbPath) == null) {
return;
}
//设置白名单
SQLiteLintAndroidCoreManager.INSTANCE.get(concernedDbPath).setWhiteList(xmlResId);
}
/**
* 增加白名单
* @param xmlResId
*/
public void setWhiteList(final int xmlResId) {
CheckerWhiteListLogic.setWhiteList(mContext, mConcernedDbPath, xmlResId);
}
public static void setWhiteList(Context context, final String concernedDbPath, final int xmlResId) {
....
//将解析完白名单之后的结果传递到native 层
addToNative(concernedDbPath, whiteListMap);
}
这里首先会先将xml 白名单使用xml解析器,解析出来,之后调用addToNative 告知白名单的设置
/**
* 将解析白名单之后的结果 传递到native层
* @param concernedDbPath
* @param whiteListMap
*/
private static void addToNative(final String concernedDbPath, Map<String, List<String>> whiteListMap) {
if (whiteListMap == null) {
return;
}
//将map 转成 数组的形式
...
//传递到native 层,设置当前检查数据库的白名单
SQLiteLintNativeBridge.nativeAddToWhiteList(concernedDbPath, checkerArr, whiteListArr);
}
void Java_com_tencent_sqlitelint_SQLiteLintNativeBridge_nativeAddToWhiteList(JNIEnv *env, jobject, jstring db_path, jobjectArray check_name_arr, jobjectArray white_list_arr) {
...
//解析完之后,传递白名单的结果
SetWhiteList(dbPath, whiteList);
free(dbPath);
}
void SetWhiteList(const char* db_path, const std::map<std::string, std::set<std::string>>& white_list) {
LintManager::Get()->SetWhiteList(db_path, white_list);
}
void LintManager::SetWhiteList(const char *db_path, const std::map<std::string, std::set<std::string>> &white_list) {
//加锁
std::unique_lock<std::mutex> lock(lints_mutex_);
//遍历是否能从 lints_ 集合中找到 db_path 对应的 Lint 对象
std::map<const std::string, Lint*>::iterator it = lints_.find(db_path);
//没有找到
if (it == lints_.end()) {
lock.unlock();
sWarn("LintManager::SetWhiteList lint not installed; dbPath: %s", db_path);
return;
}
//找到了,设置白名单
it->second->SetWhiteList(white_list);
//解锁
lock.unlock();
}
void Lint::SetWhiteList(const std::map<std::string, std::set<std::string>> &white_list) {
env_.SetWhiteList(white_list);
}
void LintEnv::SetWhiteList(const std::map<std::string, std::set<std::string>> &white_list) {
white_list_mgr_.SetWhiteList(white_list);
}
这里white_list_mgr_ 为 LintEnv 中的一个成员变量 WhiteListMgr white_list_mgr_,而 WhiteListMgr 中有一个成员变量 std::map<std::string, std::set<std::string>> white_list_;
专门用来存储白名单的内容,继续回到addConcernedDB()函数,执行
SQLiteLint.enableCheckers(concernedDbPath, concernDb.getEnableCheckerList());
public static void enableCheckers(String concernedDbPath, final List<String> enableCheckerList) {
...
SQLiteLintAndroidCoreManager.INSTANCE.get(concernedDbPath).enableCheckers(enableCheckerList);
}
public void enableCheckers(List<String> enableCheckers) {
//将list 结构 转成 数组的形式
String[] enableCheckerArr = new String[enableCheckers.size()];
for (int i = 0; i < enableCheckers.size(); i++) {
enableCheckerArr[i] = enableCheckers.get(i);
}
//将当前 要检测的内容 传递到 native 层
SQLiteLintNativeBridge.nativeEnableCheckers(mConcernedDbPath, enableCheckerArr);
}
void Java_com_tencent_sqlitelint_SQLiteLintNativeBridge_nativeEnableCheckers(JNIEnv *env, jobject, jstring dbPathStr, jobjectArray enableCheckerArr) {
char *dbPath = jstringToChars(env, dbPathStr);
jint j_check_name_arr_count = env->GetArrayLength(enableCheckerArr);
for (jint i = 0 ; i < j_check_name_arr_count ; i++) {
jstring j_checker_name = (jstring) env->GetObjectArrayElement(enableCheckerArr, i);
char *checkerName = jstringToChars(env, j_checker_name);
//告知当前dbPath 路径指定的数据库 检测的内容
EnableChecker(dbPath, checkerName);
free(checkerName);
}
free(dbPath);
}
就会通过EnableChecker()设置当前 数据库 dbPath 对应的检测内容
void EnableChecker(const char* db_path, const std::string& checker_name) {
LintManager::Get()->EnableChecker(db_path, checker_name);
}
void LintManager::EnableChecker(const char *db_path, const std::string &checker_name) {
std::unique_lock<std::mutex> lock(lints_mutex_);
//遍历是否能从 lints_ 集合中找到 db_path 对应的 Lint 对象
std::map<const std::string, Lint*>::iterator it = lints_.find(db_path);
//没有找到
if (it == lints_.end()) {
lock.unlock();
sWarn("LintManager::EnableChecker lint not installed; dbPath: %s", db_path);
return;
}
//找到了,注册检测的内容
it->second->RegisterChecker(checker_name);
lock.unlock();
}
这里就会根据传递过来的字符串匹配,从而注册对应的检测对象
void Lint::RegisterChecker(const std::string &checker_name) {
sDebug("Lint::RegisterChecker check_name: %s", checker_name.c_str());
if (CheckerName::kExplainQueryPlanCheckerName == checker_name) {// 索引检查
RegisterChecker(new ExplainQueryPlanChecker());
} else if (CheckerName::kRedundantIndexCheckerName == checker_name) {//冗余检查
RegisterChecker(new RedundantIndexChecker());
} else if (CheckerName::kAvoidAutoIncrementCheckerName == checker_name) {//AutoIncrement 检查
RegisterChecker(new AvoidAutoIncrementChecker());
} else if (CheckerName::kAvoidSelectAllCheckerName == checker_name) {//select * 检查
RegisterChecker(new AvoidSelectAllChecker());
} else if (CheckerName::kWithoutRowIdBetterCheckerName == checker_name) {//without rowId 检查
RegisterChecker(new WithoutRowIdBetterChecker());
} else if (CheckerName::kPreparedStatementBetterCheckerName == checker_name) {//preparedStatement 检查
RegisterChecker(new PreparedStatementBetterChecker());
}
}
void Lint::RegisterChecker(Checker* checker) {
std::map<CheckScene, std::vector<Checker*>>::iterator iter = checkers_.find(checker->GetCheckScene());
// 根据 checker 分类,如果找到了,就直接添加
if (iter != checkers_.end()) {
iter->second.push_back(checker);
} else {
//如果没有找到,构建一个数组,再添加到总的 checkers_ 数组中
std::vector<Checker*> v;
v.push_back(checker);
checkers_.insert(std::pair<CheckScene, std::vector<Checker*>>(checker->GetCheckScene(), v));
}
}
其中 checkers_ 为 Lint 的一个成员变量,定义为 std::map<CheckScene, std::vector<Checker*>> checkers_; 用来存储要检测的内容,已经检测对应的类,
这样java对应的初始化已经执行完毕
线程的执行
我们知道在构建当前数据库路径对应的Lint对象的时候,创建了俩个线程,其中一个线程的run方法
/**
* 在 check_thread_ 线程中 执行
*/
void Lint::Check() {
//这边又构建一个 init_check_thread_ 的线程,线程执行的时候,会执行 InitCheck 函数
init_check_thread_ = new std::thread(&Lint::InitCheck, this);
//用来存储要分发结果的集合
std::vector<Issue>* published_issues = new std::vector<Issue>;
std::unique_ptr<SqlInfo> sql_info;
SqlInfo simple_sql_info;
//这下面一般是检查是否有结果,有就分发出去之类的
while (true) {
//从queue 结果队列中 获取到内容,如果 队列中有元素,取出对头的元素,然后辅助给 sql_info ,如果没有元素,则会阻塞在这里
int ret = TakeSqlInfo(sql_info);
if (ret != 0) {
sError("check exit");
break;
}
//取出了队列中的头部的元素,下面是执行分发
...
}
}
//虽然用了双端队列,还是得确认线程安全影响大不大
int Lint::TakeSqlInfo(std::unique_ptr<SqlInfo> &sql_info) {
//加锁
std::unique_lock<std::mutex> lock(queue_mutex_);
//如果当前为推出的状态,返回-1
if (exit_) {
return -1;
}
//如果队里为空,利用 queue_cv_ 将线程阻塞
while (queue_.empty()) {
sInfo("Lint::TakeSqlInfo queue empty and wait");
queue_cv_.wait(lock);
if (exit_) {
return -1;
}
}
//如果队列不为空,移除队头的元素,辅助给 sql_info
sql_info = std::move(queue_.front());
queue_.pop_front();
return 0;
}
所以这里在执行TakeSqlInfo()的时候,因为没有queue中没有内容,会导致阻塞,接下来我们再来分析另一个线程
/**
* init_check_thread_ 线程启动的时候,执行
*/
void Lint::InitCheck() {
sVerbose("Lint::Check() init check");
//休眠4秒
std::this_thread::sleep_for(std::chrono::seconds(4));
//构建一个集合用来收集结果
std::vector<Issue>* published_issues = new std::vector<Issue>;
//安排检查, 类型为 kAfterInit 的有 AvoidAutoIncrementChecker , WithoutRowIdBetterChecker ,RedundantIndexChecker
ScheduleCheckers(CheckScene::kAfterInit, SqlInfo(), published_issues);
//如果published_issues 结果 不为空,说明检查到了有不合格的内容
if (!published_issues->empty()) {
sInfo("New check some diagnosis out!");
if (issued_callback_) {
//将结果传递回去
issued_callback_(env_.GetDbPath().c_str(), *published_issues);
}
}
delete published_issues;
}
这里会先调用 ScheduleCheckers(CheckScene::kAfterInit, SqlInfo(), published_issues); 这里注意第一个参数为CheckScene::kAfterInit,这个标识是否为初始化的时候就可以检测,
对于索引的检测,AutoCrenemt等的检测,可以在初始化的时候就检测,这个时机点在检测的每一个类中都有指定,比如
CheckScene AvoidAutoIncrementChecker::GetCheckScene() {
return CheckScene::kAfterInit;
}
/**
* 当前的检查方式为抽样检查
* @return
*/
CheckScene PreparedStatementBetterChecker::GetCheckScene() {
return CheckScene::kSample;
}
再次及时第三个参数为 published_issues 为一个集合用来存储检测的结果
void Lint::ScheduleCheckers(const CheckScene check_scene, const SqlInfo& sql_info, std::vector<Issue> *published_issues) {
std::map<CheckScene, std::vector<Checker*>>::iterator it = checkers_.find(check_scene);
if (it == checkers_.end()) {
return;
}
// 从 checkers_ 得到 满足 check_scene 集合
std::vector<Checker*> scene_checkers = it->second;
size_t scene_checkers_cnt = scene_checkers.size();
//遍历执行对应的 Check 函数
for (size_t i=0;i < scene_checkers_cnt;i++) {
Checker* checker = scene_checkers[i];
//当前比较的类型不能为 kSample的形势,也即是不为抽样检查
if (check_scene != CheckScene::kSample || (env_.GetSqlCnt() % checker->GetSqlCntToSample() == 0)) {
checker->Check(env_, sql_info, published_issues);
}
}
}
由于类型为 kAfterInit 的有 AvoidAutoIncrementChecker , WithoutRowIdBetterChecker ,RedundantIndexChecker,所以就会对应的执行 Check函数
AutoIncrement 检测
void AvoidAutoIncrementChecker::Check(LintEnv &env, const SqlInfo &sql_info, std::vector<Issue> *issues) {
//获取到当前数据库 中表的信息集合
std::vector<TableInfo> tables = env.GetTablesInfo();
sVerbose("AvoidAutoIncrementChecker::Check tables count: %d", tables.size());
std::string create_sql;
//遍历这些表
for (const TableInfo& table_info : tables) {
//检查这个table 是否在白名单中
if (env.IsInWhiteList(kCheckerName, table_info.table_name_)) {
sVerbose("AvoidAutoIncrementChecker::Check in white list: %s", table_info.table_name_.c_str());
continue;
}
//获取到当前创建的sql语句,在 select name, sql from sqlite_master where type='table' 中就能获取到全部表的创建信息
create_sql = table_info.create_sql_;
//转成小写
ToLowerCase(create_sql);
//从创建表的sql 语句中 查找是否有 autoincrement 关键字
if (create_sql.find(kAutoIncrementKeyWord) != std::string::npos) {
//如果找到了,发布一个结果
PublishIssue(env, table_info.table_name_, issues);
}
}
}
既然是提前检测,那么肯定是根据当前数据库的创建表信息,属性等来检测,所以首先要获取到表的信息
std::vector<TableInfo> tables = env.GetTablesInfo();
const std::vector<TableInfo> LintEnv::GetTablesInfo() {
//加锁
std::unique_lock<std::mutex> lock(lints_mutex_);
//如果当前数据库 表信息为空,收集表信息
if (tables_info_.empty()) {
CollectTablesInfo();
}
return tables_info_;
}
由于我们当前第一次访问,所以会执行CollectTablesInfo() 执行收集的操作
/**
* 收集当前数据库表的信息
*/
void LintEnv::CollectTablesInfo() {
...
//用来接受错误的信息
char *err_msg = nullptr;
//查询表的信息
int r = GetQuery(kSelectTablesSql, OnSelectTablesCallback, &tables_info_, &err_msg);
//处理查询的错误信息
if (!DealWithGetQuery(r, err_msg, kSelectTablesSql)) {
return;
}
//用来标记查询数据库列的sql
std::string select_columns_sql;
//用来查询索引的sql
std::string select_index_sql;
std::string select_index_info_sql;
//遍历当前 tables_info_ 集合
for (TableInfo &table_info : tables_info_) {
//查询数据库列的 sql语句
select_columns_sql = "PRAGMA table_info(" + table_info.table_name_ + ")";
//执行查询操作,这里传递的参数 为 table_info,查询完之后填充这个表中列的信息
r = GetQuery(select_columns_sql, OnSelectColumnsCallback, &table_info, &err_msg);
//处理查询列错误的信息
if (!DealWithGetQuery(r, err_msg, select_columns_sql)) {
return;
}
//接下来查询表的 索引信息
select_index_sql = "PRAGMA index_list(" + table_info.table_name_ + ")";
//这里的 接受处理的回调函数为 OnSelectIndexsCallback
r = GetQuery(select_index_sql, OnSelectIndexsCallback, &table_info, &err_msg);
//处理查询错误的信息
if (!DealWithGetQuery(r, err_msg, select_index_sql)) {
return;
}
//遍历当前表中的索引名称,判断是否为组合索引,如果是获取到组合索引中的元素,
for (IndexInfo &index_info : table_info.indexs_) {
select_index_info_sql = "PRAGMA index_info(" + index_info.index_name_ + ")";
r = GetQuery(select_index_info_sql, OnSelectIndexInfoCallback, &index_info, &err_msg);
//处理错误的信息
if (!DealWithGetQuery(r, err_msg, select_index_info_sql)) {
return;
}
}
}
}
首先执行 int r = GetQuery(kSelectTablesSql, OnSelectTablesCallback, &tables_info_, &err_msg);这里 kSelectTablesSql值为,这也即是要查询的内容
static constexpr const char* const kSelectTablesSql = "select name, sql from sqlite_master where type='table'";
第二个参数OnSelectTablesCallback 为 执行了这个查询之后,进行调用的函数指针,而tables_info_ 的定义为,也即是用来填充查询之后表的内容
//用来存储当前数据库 包含表信息的集合
std::vector<TableInfo> tables_info_;
int LintEnv::GetQuery(const std::string &query_sql, const SqlExecutionCallback &callback, void *para, char **errMsg) {
...
//执行查询
return SQLite3ExecSql(db_path_.c_str(), query_sql.c_str(), callback, para, errMsg);
}
int LintEnv::SQLite3ExecSql(const char *db_path, const char *sql, const SqlExecutionCallback &callback, void *para, char **errmsg) {
//如果有设置全局sql 执行的代理,执行这个代理
if (kSqlExecutionDelegate) {
return kSqlExecutionDelegate(db_path, sql, callback, para, errmsg);
} else {
sError("LintEnv::SQLite3ExecSql kSqlExecutionDelegate not set!!!");
return -1;
}
}
由于前面我们有设置kSqlExecutionDelegate 的值,这个值就是用来委托java层执行sql语句的函数指针
int SqliteLintExecSql(const char *file_name, const char *sql, SqlExecutionCallback callback, void *para, char **err_msg) {
//查询之后函数指针,这里将地址转为 整数 传递到java层
int64_t exec_sql_callback_ptr = (int64_t) (intptr_t) callback;
//参数
int64_t para_ptr = (int64_t) (intptr_t) para;
...
//获取到env
JNIEnv *env = nullptr;
bool attached = false;
jint ret = kJvm->GetEnv((void **) &env, JNI_VERSION_1_6);
if (ret == JNI_EDETACHED) {
jint ret = kJvm->AttachCurrentThread(&env, nullptr);
assert(ret == JNI_OK);
(void) ret;
attached = true;
}
//调用 SQLiteLintNativeBridge 中的 sqliteLintExecSql 函数
jstring filename_str = charsToJstring(env,file_name);
jstring sql_str = charsToJstring(env,sql);
jobjectArray retArray = (jobjectArray) env->CallObjectMethod(kExecSqlObj, kExecSqlMethodID,filename_str, sql_str,
callback ? JNI_TRUE : JNI_FALSE, exec_sql_callback_ptr,para_ptr);
env->DeleteLocalRef(filename_str);
env->DeleteLocalRef(sql_str);
if (!retArray) {
LOGE("sqliteLintExecSql retArray is null");
if (attached) kJvm->DetachCurrentThread();
return -1;
}
...
return -1;
}
可以看到这里将这些函数指针转成int64,然后通过调用java层SQLiteLintNativeBridge 的sqliteLintExecSql 函数来执行查询
/**
* JNI 层方法调用 ,native 没有办法查询数据库,只能通知java层来查询,查询完之后将结果传到native 层
* @param dbPath
* @param sql
* @param needCallBack 是否需要回调
* @param execSqlCallbackPtr 底层回调函数的地址
* @param paraPtr 底层参数的地址
* @return
*/
private String[] sqliteLintExecSql(String dbPath, String sql, boolean needCallBack, long execSqlCallbackPtr,long paraPtr) {
String[] retObj = new String[2];
try {
...
ISQLiteExecutionDelegate executionDelegate = null;
//获取到当前 dbPath 对应的 SQLiteLintAndroidCore 对象,然后获取到当前sql 执行的委托对象
SQLiteLintAndroidCore core = SQLiteLintAndroidCoreManager.INSTANCE.get(dbPath);
if (core != null) {
executionDelegate = core.getSQLiteExecutionDelegate();
}
//委托对象为空,直接返回
if (executionDelegate == null) {
SLog.w(TAG, "sqliteLintExecSql mExecSqlImp is null");
return retObj;
}
//不为空
if (needCallBack) {
try {
//执行真正的查询操作
Cursor cu = executionDelegate.rawQuery(sql);
//判断查询的结果
if (cu == null || cu.getCount() < 0) {
//查询结果出错, 返回值为 -1
SLog.w(TAG, "sqliteLintExecSql cu is null");
retObj[0] = "Cursor is null";
} else {
//查询到了结果,这里传递了cursor
doExecSqlCallback(execSqlCallbackPtr,paraPtr, dbPath, cu);
//将最终的结果 变为0,代表查询成功
retObj[1] = "0";
}
//关闭Cursor
if (cu != null) {
cu.close();
}
} catch (Exception e) {
//出现了错误,传递错误的信息
SLog.w(TAG, "sqliteLintExecSql rawQuery exp: %s", e.getMessage());
retObj[0] = e.getMessage();
}
} else {
//如果不需要回调
try {
//那就单纯的执行他,执行的结果也直接设置为0
executionDelegate.execSQL(sql);
retObj[1] = "0";
} catch (SQLException e) {
SLog.w(TAG, "sqliteLintExecSql execSQL exp: %s", e.getMessage());
retObj[0] = e.getMessage();
}
}
} catch (Throwable e) {
SLog.e(TAG, "sqliteLintExecSql ex ", e.getMessage());
}
return retObj;
}
这里的查询又通过 executionDelegate.rawQuery(sql); 来执行,而executionDelegate 前面有提到过 SimpleSQLiteExecutionDelegate对象
public final class SimpleSQLiteExecutionDelegate implements ISQLiteExecutionDelegate {
private static final String TAG = "SQLiteLint.SimpleSQLiteExecutionDelegate";
private final SQLiteDatabase mDb;
public SimpleSQLiteExecutionDelegate(SQLiteDatabase db) {
assert db != null;
mDb = db;
}
@Override
public Cursor rawQuery(String selection, String... selectionArgs) throws SQLException {
if (!mDb.isOpen()) {
SLog.w(TAG, "rawQuery db close");
return null;
}
//最终调用了 SQLiteDatabase rawQuery 来执行查询
return mDb.rawQuery(selection, selectionArgs);
}
...
}
在当前的demo 中 执行 select name, sql from sqlite_master where type=’table’ 获取到结果为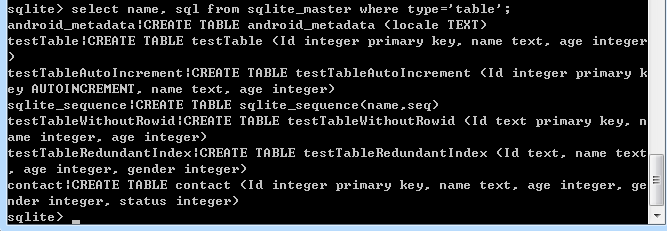
可以看到这里能获取到 创建表的语句,接着当我们获取到结果之后,又会执行 doExecSqlCallback(execSqlCallbackPtr,paraPtr, dbPath, cu);会将返回的内容解析出来,接着会调用
//解析了一条数据,就传递到native层 execSqlCallback(execSqlCallbackPtr, paraPtr, dbName, columnCount, value, name);
extern "C" {
void Java_com_tencent_sqlitelint_SQLiteLintNativeBridge_execSqlCallback(JNIEnv *env, jobject, jlong exec_sql_callback_ptr, jlong para_ptr, jstring name, jint n_column,
jobjectArray column_value, jobjectArray column_name) {
...
//将回调地址直接强转为 SqlExecutionCallback
SqlExecutionCallback exec_sql_callback = (SqlExecutionCallback) (intptr_t) exec_sql_callback_ptr;
if (!exec_sql_callback) {
LOGE("execSqlCallback execSqlCallback is NULL");
return;
}
//参数也是
void* para = (void *) (intptr_t) para_ptr;
if (!para) {
LOGE("execSqlCallback para is NULL");
return;
}
...
//又执行查询结果的回调
exec_sql_callback(para, n_column, p_column_value, p_column_name);
...
}
这里的exec_sql_callback 即为我们前面传递的 OnSelectTablesCallback 函数,所以就会执行到对应的函数
int OnSelectTablesCallback(void *para, int n_column, char **column_value, char **column_name) {
...
//创建一个 TableInfo 对象
TableInfo table_info;
//获取到表明
table_info.table_name_ = (column_value[0] == nullptr ? "" : column_value[0]);
//如果当前获取到的表名 为 "sqlite_master", "sqlite_sequence", "android_metadata" 中的一个 ,直接返回,因为这些不是我们创建的表,是属于系统
if (ReserveSqlManager::IsReservedTable(table_info.table_name_)) {
return 0;
}
//如果到了这里说明表是用户创建的表
table_info.create_sql_ = (column_value[1] == nullptr ? "" : column_value[1]);
//将para 参数转为 std::vector<TableInfo>
std::vector<TableInfo> *infoList = reinterpret_cast<std::vector<TableInfo> *>(para);
//添加到集合中
infoList->push_back(table_info);
return 0;
}
这里我们构建了一个TableInfo 对象,然后从传递过来的结果中赋值 对应的创建表sql语句,之后添加到集合TableInfo中,这样数据库的表信息就收集完毕了
回到 void LintEnv::CollectTablesInfo() 函数,收集了当前数据库中所拥有的表之后,继续往下面执行
//遍历当前 tables_info_ 集合
for (TableInfo &table_info : tables_info_) {
//查询数据库列的 sql语句
select_columns_sql = "PRAGMA table_info(" + table_info.table_name_ + ")";
//执行查询操作,这里传递的参数 为 table_info,查询完之后填充这个表中列的信息
r = GetQuery(select_columns_sql, OnSelectColumnsCallback, &table_info, &err_msg);
//处理查询列错误的信息
if (!DealWithGetQuery(r, err_msg, select_columns_sql)) {
return;
}
//接下来查询表的 索引信息
select_index_sql = "PRAGMA index_list(" + table_info.table_name_ + ")";
//这里的 接受处理的回调函数为 OnSelectIndexsCallback
r = GetQuery(select_index_sql, OnSelectIndexsCallback, &table_info, &err_msg);
//处理查询错误的信息
if (!DealWithGetQuery(r, err_msg, select_index_sql)) {
return;
}
//遍历当前表中的索引名称,判断是否为组合索引,如果是获取到组合索引中的元素,
for (IndexInfo &index_info : table_info.indexs_) {
select_index_info_sql = "PRAGMA index_info(" + index_info.index_name_ + ")";
r = GetQuery(select_index_info_sql, OnSelectIndexInfoCallback, &index_info, &err_msg);
//处理错误的信息
if (!DealWithGetQuery(r, err_msg, select_index_info_sql)) {
return;
}
}
}
之后执行查询
select_columns_sql = "PRAGMA table_info(" + table_info.table_name_ + ")";
//执行查询操作,这里传递的参数 为 table_info,查询完之后填充这个表中列的信息
r = GetQuery(select_columns_sql, OnSelectColumnsCallback, &table_info, &err_msg);
PRAGMA table_info(testTable) 查询的结果 ,从下面的几个可以看出,这个语句可以查询出当前表的列,type等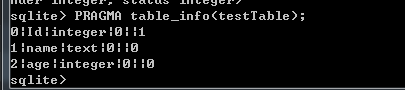
至于查询的过程就不重复了,查询成功之后,就会回调执行 OnSelectColumnsCallback()函数,进一步的填充 代表当前表信息的 table_info 对象
int OnSelectColumnsCallback(void *para, int n_column, char **column_value, char **column_name) {
if (para == nullptr) {
sError("OnSelectColumnsCallback para is null");
return -1;
}
//将参数转转为 TableInfo
TableInfo *table_info = reinterpret_cast<TableInfo *>(para);
//接下来填充 table_info中 columns_ 成员的值
ColumnInfo column_info;
int columns_assigned = 0;
for (int i = 0; i < n_column; i++) {
if (strcmp("name", column_name[i]) == 0) {//填充name
column_info.name_ = (nullptr != column_value[i] ? column_value[i] : "");
columns_assigned++;
} else if (strcmp("type", column_name[i]) == 0) {//填充type
column_info.type_ = (nullptr != column_value[i] ? column_value[i] : "");
columns_assigned++;
} else if (strcmp("pk", column_name[i]) == 0) {//填充 primary_key
column_info.is_primary_key_ = column_value[i][0] != '0';
columns_assigned++;
}
if (columns_assigned == 3) {
break;
}
}
table_info->columns_.push_back(column_info);
return 0;
}
接着又执行
select_index_sql = "PRAGMA index_list(" + table_info.table_name_ + ")";
//这里的 接受处理的回调函数为 OnSelectIndexsCallback
r = GetQuery(select_index_sql, OnSelectIndexsCallback, &table_info, &err_msg);
“PRAGMA index_list(“ + table_info.tablename + “)”;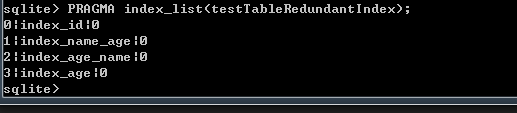
查询完之后,就会执行 OnSelectIndexsCallback 函数指针,进一步的填充 table_info对象
int OnSelectIndexsCallback(void *para, int n_column, char **column_value, char **column_name) {
if (para == nullptr) {
sError("OnSelectIndexsCallback para is null");
return -1;
}
IndexInfo index_info;
int columns_assigned = 0;
for (int i = 0; i < n_column; i++) {
if (strcmp("name", column_name[i]) == 0) {//索引的名称
index_info.index_name_ = (nullptr != column_value[i] ? column_value[i] : "");
columns_assigned++;
} else if (strcmp("seq", column_name[i]) == 0) {//索引的顺序
index_info.seq_ = atoi(column_value[i]);
columns_assigned++;
} else if (strcmp("unique", column_name[i]) == 0) {//索引是否唯一
index_info.is_unique_ = column_value[i][0] != '0';
columns_assigned++;
}
if (columns_assigned == 3) {
break;
}
}
//将参数转转为 TableInfo
TableInfo* table_info = reinterpret_cast<TableInfo *>(para);
sVerbose("OnSelectIndexsCallback index : %s", index_info.index_name_.c_str());
//填充当前表创建的索引信息
table_info->indexs_.push_back(index_info);
return 0;
}
接着遍历获取到当前表的索引,判断是否为组合索引
select_index_info_sql = "PRAGMA index_info(" + index_info.index_name_ + ")";
r = GetQuery(select_index_info_sql, OnSelectIndexInfoCallback, &index_info, &err_msg);
“PRAGMA index_info(“ + index_info.indexname + “)”;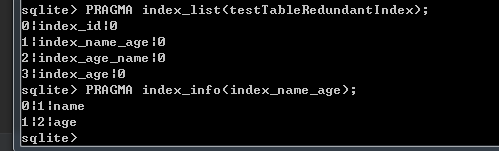
查询完之后,回调执行 OnSelectIndexInfoCallback 函数,进一步的填充 table_info对象
int OnSelectIndexInfoCallback(void* para, int n_column, char** column_value, char** column_name) {
if (para == nullptr) {
sError("OnSelectIndexsCallback para is null");
return -1;
}
IndexElement index_element;
int columns_assigned = 0;
for (int i = 0; i < n_column; i++) {
if (strcmp("seqno", column_name[i]) == 0) {//位置
index_element.pos_ = atoi(column_value[i]);
columns_assigned ++;
}
else if (strcmp("cid", column_name[i]) == 0) {//对应列的索引
index_element.column_index_ = atoi(column_value[i]);
columns_assigned ++;
}
else if (strcmp("name", column_name[i]) == 0) {//列的名称
index_element.column_name_ = (nullptr != column_value[i] ? column_value[i] : "");
columns_assigned ++;
}
if (columns_assigned == 3) {
break;
}
}
//添加到TableInfo 中的 IndexInfo 数组中
IndexInfo* index_info = reinterpret_cast<IndexInfo*>(para);
if(index_info) {
index_info->AddIndexElement(index_element);
} else{
sError("onCollectIndexInfoCallback indexInfo is null");
}
return 0;
}
在这些信息都收集完之后,就可以执行分析了,继续回到前面
检查 AutoIncrement
void AvoidAutoIncrementChecker::Check(LintEnv &env, const SqlInfo &sql_info, std::vector<Issue> *issues) {
//获取到当前数据库 中表的信息集合
std::vector<TableInfo> tables = env.GetTablesInfo();
std::string create_sql;
//遍历这些表
for (const TableInfo& table_info : tables) {
//检查这个table 是否在白名单中
if (env.IsInWhiteList(kCheckerName, table_info.table_name_)) {
sVerbose("AvoidAutoIncrementChecker::Check in white list: %s", table_info.table_name_.c_str());
continue;
}
//获取到当前创建的sql语句,在 select name, sql from sqlite_master where type='table' 中就能获取到全部表的创建信息
create_sql = table_info.create_sql_;
//转成小写
ToLowerCase(create_sql);
//从创建表的sql 语句中 查找是否有 autoincrement 关键字
if (create_sql.find(kAutoIncrementKeyWord) != std::string::npos) {
//如果找到了,发布一个结果
PublishIssue(env, table_info.table_name_, issues);
}
}
}
对于检测的内容也明了,就是通过你的创建表的sql中判断是否有autoincrement 关键字,如果有就执行 PublishIssue(env, table_info.table_name_, issues);
void AvoidAutoIncrementChecker::PublishIssue(const LintEnv& env, const std::string &table_name, std::vector<Issue> *issues) {
std::string desc = "Table(" + table_name + ") has a column which is AutoIncrement." + "It's not really recommended.";
Issue issue;
issue.id = GenIssueId(env.GetDbFileName(), kCheckerName, table_name);
issue.db_path = env.GetDbPath();
//当前创建的时间
issue.create_time = GetSysTimeMillisecond();
//等级
issue.level = IssueLevel::kTips;
//当前的类型
issue.type = IssueType::kAvoidAutoIncrement;
//数据库名
issue.table = table_name;
//详细的描述信息
issue.desc = desc;
//添加到集合中
issues->push_back(issue);
}
这里的 issues 为我们传递进来的,所以这里就会往这个集合添加元素,继续回到我们的线程执行函数
void Lint::InitCheck() {
sVerbose("Lint::Check() init check");
//休眠4秒
std::this_thread::sleep_for(std::chrono::seconds(4));
//构建一个集合用来收集结果
std::vector<Issue>* published_issues = new std::vector<Issue>;
//安排检查, 类型为 kAfterInit 的有 AvoidAutoIncrementChecker , WithoutRowIdBetterChecker ,RedundantIndexChecker
ScheduleCheckers(CheckScene::kAfterInit, SqlInfo(), published_issues);
//如果published_issues 结果 不为空,说明检查到了有不合格的内容
if (!published_issues->empty()) {
sInfo("New check some diagnosis out!");
if (issued_callback_) {
//将结果传递回去
issued_callback_(env_.GetDbPath().c_str(), *published_issues);
}
}
delete published_issues;
}
这样published_issues 集合中就有内容了,下面就可以将结果传递出去了 issued_callback_(env_.GetDbPath().c_str(), *published_issues);
/**
* 函数指针,用于进一步的中转结果
* @param db_path
* @param published_issues
*/
void OnIssuePublish(const char* db_path, std::vector<Issue> published_issues) {
...
//获取到Env
bool attached = false;
JNIEnv* env = nullptr;
jint jRet = kJvm->GetEnv((void **) &env, JNI_VERSION_1_6);
if (jRet == JNI_EDETACHED) {
LOGD("OnIssuePublish GetEnv JNI_EDETACHED");
jint jAttachRet = kJvm->AttachCurrentThread(&env, nullptr);
if (jAttachRet != JNI_OK) {
LOGE("OnIssuePublish AttachCurrentThread !JNI_OK");
return;
} else {
attached = true;
}
} else if (jRet != JNI_OK) {
LOGE("OnIssuePublish GetEnv !JNI_OK");
return;
}
LOGV("OnIssuePublish issue size %d", published_issues.size());
//构建一个ArrayList
jclass listCls = env->FindClass("java/util/ArrayList");
jobject jIssueList = env->NewObject(listCls, kListConstruct);
//将published_issues 集合中的每一个Issure 的信息,添加到 ArrayList中
for (std::vector<Issue>::iterator it = published_issues.begin(); it != published_issues.end(); it++) {
jstring id = charsToJstring(env,it->id.c_str());
jstring dbPath = charsToJstring(env,it->db_path.c_str());
jint level = it->level;
jint type = it->type;
jstring sql = charsToJstring(env,it->sql.c_str());
jstring table = charsToJstring(env,it->table.c_str());
jstring desc = charsToJstring(env,it->desc.c_str());
jstring detail = charsToJstring(env,it->detail.c_str());
jstring advice = charsToJstring(env,it->advice.c_str());
jlong createTime = it->create_time;
jstring extInfo = charsToJstring(env, it->ext_info.c_str());
jlong sqlTimeCost = it->sql_time_cost;
jboolean isInMainThread = it->is_in_main_thread;
//构建以java层 SQLiteLintIssue对象
jobject diagnosisObj = env->NewObject(kIssueClass, kMethodIDIssueConstruct, id, dbPath,
level, type, sql, table, desc, detail, advice, createTime, extInfo, sqlTimeCost, isInMainThread);
LOGV("OnIssuePublish id=%s", it->id.c_str());
//执行 ArrayList 的 Add 函数,添加到 ArrayList 集合中
env->CallBooleanMethod(jIssueList, kListAdd, diagnosisObj);
env->DeleteLocalRef(id);
env->DeleteLocalRef(dbPath);
env->DeleteLocalRef(sql);
env->DeleteLocalRef(table);
env->DeleteLocalRef(desc);
env->DeleteLocalRef(detail);
env->DeleteLocalRef(advice);
env->DeleteLocalRef(extInfo);
}
//调用 SQLiteLintNativeBridge 的 onPublishIssue 函数,传递结果
jstring jDbPath = charsToJstring(env, db_path);
env->CallStaticVoidMethod(kJavaBridgeClass, kMethodIDOnPublishIssueCallback, jDbPath, jIssueList);
env->DeleteLocalRef(jDbPath);
if (attached) kJvm->DetachCurrentThread();
}
最终会通过JNI的调用java 到 SQLiteLintNativeBridge 中的 onPublishIssue 函数
private static void onPublishIssue(final String dbName, final ArrayList<SQLiteLintIssue> publishedIssues) {
try {
SQLiteLintAndroidCoreManager.INSTANCE.get(dbName).onPublish(publishedIssues);
}catch (Throwable e) {
SLog.e(TAG, "onPublishIssue ex ", e.getMessage());
}
}
之后的逻辑就不看了,大致就是会先存储到内部的数据库,然后将这些结果显示出来,包括冗余检查,Without RowId 这里就不检测了
对于我们事实的sql 语句检查是怎么样做到的呢
在demo 中 有这样的方法,会按钮按下的时候触发
private void testParser() {
//获取到 要测试的 sql 数组
String[] list = TestSQLiteLintHelper.getTestParserList();
//分别执行
for (String sql : list) {
MatrixLog.i(TAG, "testParser, sql = " + sql);
SQLiteLint.notifySqlExecution(TestDBHelper.get().getWritableDatabase().getPath(), sql, 10);
}
}
//获取到要测试的sql 语句
public static String[] getTestParserList() {
String[] list = new String[]{
"select a,b,c from test where id > 100 and id < 200 or id between 300 and 400 or id = 1000 ORDER BY c1,c2,c3 desc limit 10 offset 2;",
"select t1.a ,t2.b from table1 as t1,table2 as t2 where t1.tid = t2.tid and t1.tid='aaa' or t2.tid=12;",
"select count(*) from test union select id from test where id not IN (select id from test1);",
"select title, year from film where starring like 'Jodie%' and year >= 1985 order by year desc limit 10;",
"SELECT * FROM table1 WHERE column2 not LIKE 'rt' OR column3 LIKE 'rc' AND column1 = 'yy' GROUP BY column2 ORDER BY column2;",
"SELECT * FROM nosharding_test WHERE id = 1 AND(id < 50 OR id > 200);",
"SELECT * FROM test WHERE name NOT LIKE '/Hello%' ESCAPE '/';",
....
};
return list;
}
遍历每一条语句,分别执行
SQLiteLint.notifySqlExecution(TestDBHelper.get().getWritableDatabase().getPath(), sql, 10);
public static void notifySqlExecution(String concernedDbPath, String sql, int timeCost) {
//获取到当前 数据库的路径 对应的 SQLiteLintAndroidCore
if (SQLiteLintAndroidCoreManager.INSTANCE.get(concernedDbPath) == null) {
return;
}
//notifySqlExecution
SQLiteLintAndroidCoreManager.INSTANCE.get(concernedDbPath).notifySqlExecution(concernedDbPath, sql, timeCost);
}
public void notifySqlExecution(String dbPath, String sql, long timeCost) {
String extInfoStack = "null"; //get stack only when cost > 8
//timeCost 默认传递的参数为 10,所以大于8
if (timeCost >= 8) {
//这个是获取到当前的堆栈信息
extInfoStack = SQLiteLintUtil.getThrowableStack(new Throwable());
}
//传递到native 层
SQLiteLintNativeBridge.nativeNotifySqlExecute(dbPath, sql, timeCost, extInfoStack);
}
可以看到这里首先获取到java层对应的堆栈信息,然后传递给native层
void Java_com_tencent_sqlitelint_SQLiteLintNativeBridge_nativeNotifySqlExecute(JNIEnv *env, jobject, jstring dbPath
, jstring sql, jlong executeTime, jstring extInfo) {
char *filename = jstringToChars(env, dbPath);
char *ext_info = jstringToChars(env, extInfo);
char *jsql = jstringToChars(env, sql);
NotifySqlExecution(filename, jsql, executeTime, ext_info);
free(jsql);
free(ext_info);
free(filename);
}
void NotifySqlExecution(const char* db_path, const char* sql, long time_cost, const char* ext_info) {
LintManager::Get()->NotifySqlExecution(db_path, sql, time_cost, ext_info);
}
void LintManager::NotifySqlExecution(const char *db_path, const char *sql, long time_cost, const char* ext_info) {
//加锁
std::unique_lock<std::mutex> lock(lints_mutex_);
//找到当前数据库路径对应的 Lint 对象
std::map<const std::string, Lint*>::iterator it = lints_.find(db_path);
if (it == lints_.end()) {
lock.unlock();
sWarn("LintManager::NotifySqlExecution lint not installed; dbPath: %s", db_path);
return;
}
//执行测试
it->second->NotifySqlExecution(sql, time_cost, ext_info);
lock.unlock();
}
void Lint::NotifySqlExecution(const char *sql, const long time_cost, const char* ext_info) {
//参数检查
if (sql == nullptr){
sError("Lint::NotifySqlExecution sql NULL");
return;
}
//判断当前sql 是否在 reserve_sql_mgr_ 集合中 找得到,并且找到的时候 时间不能超过一秒
if (env_.IsReserveSql(sql)) {
sDebug("Lint::NotifySqlExecution a reserved sql");
return;
}
//构建一个SqlInfo 对象
SqlInfo *sql_info = new SqlInfo();
sql_info->sql_ = sql;
//对应的执行的时间
sql_info->execution_time_ = GetSysTimeMillisecond();
//对应的java 的堆栈信息
sql_info->ext_info_ = ext_info;
//对应的花费的时间
sql_info->time_cost_ = time_cost;
//标识当前的状态是否在主线程
sql_info->is_in_main_thread_ = IsInMainThread();
//加锁
std::unique_lock<std::mutex> lock(queue_mutex_);
//将这个 sql_info 添加到了 queue_ 队列中,同时执行了 notify_one ,这样检查的线程就会唤醒了
queue_.push_back(std::unique_ptr<SqlInfo>(sql_info));
queue_cv_.notify_one();
//解锁
lock.unlock();
}
这边会将传递参数,构建一个SqlInfo 对象,然后添加到 queue_ 中,前面说个还有一个线程因为queue中的内容为空,导致处于阻塞的状态,这里因为添加进去了,所以就不会阻塞了,继续回到
线程函数
void Lint::Check() {
//这边又构建一个 init_check_thread_ 的线程,线程执行的时候,会执行 InitCheck 函数
init_check_thread_ = new std::thread(&Lint::InitCheck, this);
//用来存储要分发结果的集合
std::vector<Issue>* published_issues = new std::vector<Issue>;
std::unique_ptr<SqlInfo> sql_info;
SqlInfo simple_sql_info;
//这下面一般是检查是否有结果,有就分发出去之类的
while (true) {
//从queue 结果队列中 获取到内容,如果 队列中有元素,取出对头的元素,然后辅助给 sql_info ,如果没有元素,则会阻塞在这里
int ret = TakeSqlInfo(sql_info);
if (ret != 0) {
sError("check exit");
break;
}
//取出了队列中的头部的元素,下面是执行分发
//标识当前检测的sql 语句加一
env_.IncSqlCnt();
...
ScheduleCheckers(CheckScene::kSample, *sql_info, published_issues);
const std::string& wildcard_sql = sql_info->wildcard_sql_.empty() ? sql_info->sql_ : sql_info->wildcard_sql_;
bool checked = false;
if (!checked_sql_cache_.Get(wildcard_sql, checked)) {
...
ScheduleCheckers(CheckScene::kUncheckedSql, *sql_info, published_issues);
checked_sql_cache_.Put(wildcard_sql, true);
} else {
sVerbose("Lint::Check() already checked recently");
}
if (!published_issues->empty()) {
sInfo("New check some diagnosis out!, sql=%s", sql_info->sql_.c_str());
if (issued_callback_) {
issued_callback_(env_.GetDbPath().c_str(), *published_issues);
}
}
sql_info = nullptr;
env_.CheckReleaseHistory();
}
sError("check break");
delete published_issues;
}
由于TakeSqlInfo() 返回了元素,所以会往下执行,分别执行 ScheduleCheckers(CheckScene::kSample, *sql_info, published_issues);,以及
ScheduleCheckers(CheckScene::kUncheckedSql, *sql_info, published_issues);至于检测的内容就不细看了,这里比较复杂,检测到了结果之后,就会将检测的结果通过issued_callback_
传递到java层
总结
SQLiteLint 中检测 ,索引使用问题,冗余索引问题,Autoincrement 问题,without rowid 特性不需要事实的sql语句,只需要通过读取数据库创建的表信息就可以检测,其中检测是通过JNI的方式将参数传递到java层,由java层来真正的操作数据库,查询完之后又将结果传递给Native层,对于 Select * ,prepared statement 需要事实的sql语句来分析,由于没有采用hook sqlite3_profile 所以对于要检测的sql 语句需要java层传递到native层



