打洞需知
我们前面辛辛苦苦移植了utp就是为了打洞,而打洞就会有成功或者失败,在做这个项目之前就有必要去调查下我们用户打洞可以成功的概率,而STUN就可以检测用户的网络类型,判断那些是不可以打洞那些是可以打洞成功 在了解STUN之前,我们需要了解NAT的种类。
NAT对待UDP的实现方式有4种,分别如下:Full Cone NAT
完全锥形NAT,所有从同一个内网IP和端口号发送过来的请求都会被映射成同一个外网IP和端口号,并且任何一个外网主机都可以通过这个映射的外网IP和端口号向这台内网主机发送包。
Restricted Cone NAT
限制锥形NAT,它也是所有从同一个内网IP和端口号发送过来的请求都会被映射成同一个外网IP和端口号。与完全锥形不同的是,外网主机只能够向先前已经向它发送过数据包的内网主机发送包。
Port Restricted Cone NAT
端口限制锥形NAT,与限制锥形NAT很相似,只不过它包括端口号。也就是说,一台IP地址X和端口P的外网主机想给内网主机发送包,必须是这台内网主机先前已经给这个IP地址X和端口P发送过数据包。
Symmetric NAT
对称NAT,所有从同一个内网IP和端口号发送到一个特定的目的IP和端口号的请求,都会被映射到同一个IP和端口号。如果同一台主机使用相同的源地址和端口号发送包,但是发往不同的目的地,
NAT将会使用不同的映射。此外,只有收到数据的外网主机才可以反过来向内网主机发送包。
针对以上的用户网络类型,当用户的网络类型为 Symmetric NAT 就是不能打洞的情况,而STUN就是用来检测用户的网络类型的,关于STUN的介绍网上有很多,这里就不详细介绍,而对于STUN的检测工具网络上也有很多,比如 https://github.com/mangefoo/stunclient ,下面是我们调查的结果
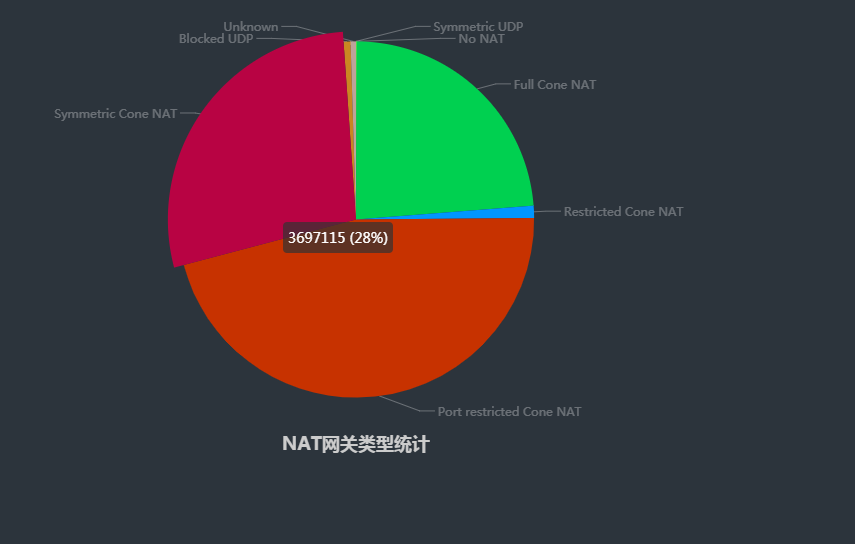
通过以上的调查结果可以知道,对于对称型的网络大致占有28%左右,也即是这部分的用户是不能打洞,那其他打洞的用户大致占有70%左右,网络上也有说针对这种对称型网络的对策,比如转发或者端口猜测等,其中转发可以由服务器来转发,但是这个不太现实,我们使用p2p下载就是为了减小带宽的问题,对应端口猜测,在移动端来说也是不太现实,数量太多,所以对应这种网络类型的,我们直接走传统的http下载
打洞的机制
首先了解下NAT的穿透
NAT的工作需要LAN网下的本地设备主动发起网络连接,然后NAT服务才会将这个连接映射到WAN口的公网IP完成转换。也就是说,如果本地主机没有主动发起连接,那么这个映射就不会存在,
那么公网上的机器就无法访问到私网上的机器。也就是说,只能是私网机器主动连接公网机器,而不能是公网机器主动连接私网机器。而为了实现公网机器主动连接私网机器,我们就需要穿透NAT,
这就是NAT穿透的由来。
目前比较好实现NAT穿透的方式是采用UDP连接对NAT进行打洞,然后完成连接。何为打洞呢?
就是为了使NAT产生一个可用的映射。具体步骤就是在私网机器上用UDP向某台公网机器发起连接,使得NAT产生一个可以使用的映射(洞)。然后通过这个映射(洞),就可以穿透NAT。至于为什么要用UDP,这是由于UDP的某些特性。UDP通信需要先绑定本地机器的端口,完成后就可以从这个端口收发数据,至于从哪里收,发到哪里,可以在收发数据的时候再决定,这也就意味着我可以用这一个端口同时和多个对象通信,只要我收发数据的时候指定不同的对象即可。当本地机器用UDP向英特网上的某个服务器发送数据的时候,这个映射不但能用来和这个服务器进行数据交互,也能用来接收其他主机发来的数据。NAT穿透就是本地主机向公网上的某台服务器发送数据,这时服务器就可以获得NAT对这台主机的映射,在之前举得例子中就是55.66.77.88:5000这个地址。由于NAT会将55.66.77.88:5000收到的数据转发至本地主机,所以公网上的其他机器可以从服务器获取到55.66.77.88:5000这个网络地址,然后通过这个网络地址向私网下的机器发出数据。
而至于为什么不用TCP,也是由于TCP的某些特性。TCP通信的步骤与UDP不同,它需要先在两个对象之间建立一个专用通道,再用这个通道收发数据。也就是说外人无法插手。这样一来,虽然其他机器可以通过服务器获取到NAT的映射对象,也没办法利用它向私网下的机器发出数据。
总结下打洞的前提
- 首先要有一个服务器,用来告知对方的公网ip
- 首先要使用udp
- 俩者应该同时发起连接,由于很难做到同时,应该有一个重试的机制
Aria2打洞的实现
由于打洞首先要有一个服务器,这个服务器主要是用来告知对方的公网的ip和端口号,而我们的tracker服务器做的就是这个工作,tracker服务器会每隔一段时间返回当前已经连接上服务器的所用用户对应的外网ip和端口号
第二打洞要使用udp,而我们移植的utp就是udp的实现,只是在udp的基础上添加了类似于tcp的逻辑,比如丢包重发,拥塞控制,滑动窗口等,使我们使用起来不用管理这些细节
第三打洞要同时发起连接,由于很难做到同时,所以对应的应该要有一个重试的机制 虽然utp连接就是一个重试的过程,默认是20秒超时,但是为了可以控制,在移植utp的时候,我也增加了utp的重试机制,具体前面有介绍,最后就是同时连接了,这里我们就要针对原先的从tracker服务器返回peer列表的时候增加一点操作了,当收到tracker服务器返回的peer列表就直接执行连接操作,这里我们在保证原有的逻辑不改变的情况下,增加了一个临时的队列,存储了peer下次应该连接的时候,当时间到的时候,这个peer就应该执行连接操作,所以这里要算出对应的主机下一次触发连接的时间下面是大概的思路
满足下次peer触发tracker时间 >= 当前系统时间)的元素:为他们新建队列,按照(下次peer触发tracker时间)进行排序,当元素满足(下次peer触发tracker时间 <= 当前系统时间)时,进行addPeer相应的tracker服务端应该记录下每一个用户连接tracker的开始时间,下面是对应的代码实现
//从tracker服务器获取到peer之后,统一调用这个方法添加peer,内部完成对应的addPeer逻辑
void DefaultPeerStorage::addPeerList(std::vector<std::shared_ptr<PeerNodeInfo>>& nodeInfos,std::chrono::seconds interval)
{
//当下次tracker再次返回peer的时候,应该要清除这个缓冲的集合,因为按理来说,应该在下次tracker触发的时候,应该要把所有的peer执行连接操作
tempPeers.clear();
A2_LOG_DEBUG(fmt("tracker getPeerTime %u",util::timeGetTime()));
for(auto& nodeInfo : nodeInfos)
{
//原本的逻辑,这个方法会执行peer的连接操作
addPeer(std::make_shared<Peer>(nodeInfo->getIpAddr(),nodeInfo->getPort()));
//当前时间的秒数
auto now_second = std::chrono::seconds(util::timeGetTime());
//peer添加的时间
auto minInterval_ = std::chrono::seconds(nodeInfo->getTimeStamp());
//2.其余满足( 下次peer触发tracker时间 >= 当前系统时间)的元素:为他们新建队列,按照(下次peer触发tracker时间)进行排序,当元素满足(下次peer触发tracker时间 <= 当前系统时间)时,进行addPeer
if(nodeInfo->getTimeStamp() != 0 && minInterval_ + interval <= now_second)
{
//算出当前的peer经历了多少次的tracker 刷新
int peerIntervalCount = (int) ((now_second - minInterval_ ) / interval);
//计算出当前peer下次刷新的tracker时间点
std::chrono::seconds trackTime = minInterval_ + interval * (peerIntervalCount+1);
A2_LOG_DEBUG(fmt("%s:%d old peer peerIntervalCount %d 下次连接时间 %ld",nodeInfo->getIpAddr().c_str(),nodeInfo->getPort(),peerIntervalCount,static_cast<long int> (trackTime.count())));
//存储到临时集合
tempPeers[nodeInfo] = std::move(trackTime);
}
}
}
//临时的队列,用来保存那些peer ,这里的key为 这些peer下次应该要触发的连接的时间,采用multimap ,是因为对于那些即将要添加的peer,他们连接的触发时间
//范围在 当前的时间到tracker的刷新时间间隔之内,所以可能会有多个peer 拥有同样的key
std::map<std::shared_ptr<PeerNodeInfo>,std::chrono::seconds> tempPeers;
接着是用来一直检测这个临时队列的peer是否到了他们要执行连接的时间
//根据当前的时间检查是否有peer 要添加的,如果有应该执行addPeer操作
void DefaultPeerStorage::checkPeerTimeToAdd() {
//如果为空,不用检查
if (tempPeers.empty()) {
return;
}
//当前时间的秒数
auto now_second = std::chrono::seconds(util::timeGetTime());
for (auto i = std::begin(tempPeers); i != std::end(tempPeers);) {
//如果当前peer 下次触发的时间小于或者等于当前的时间,要立刻执行addPeer操作
if ((*i).second <= now_second) {
A2_LOG_DEBUG(fmt("TimeToAdd %s:%d time to add Peer now time %ld",(*i).first->getIpAddr().c_str(),(*i).first->getPort(),static_cast<long int> (now_second.count())));
LOGD("TimeToAdd %s:%d time to add Peer now time %ld",(*i).first->getIpAddr().c_str(),(*i).first->getPort(),static_cast<long int> (now_second.count()));
//构建一个Peer 对象,调用对应的构造函数完成初始化 这里只是添加进来,并没有进行连接peer的操作
addPeer(std::make_shared<Peer>((*i).first->getIpAddr(),(*i).first->getPort()));
tempPeers.erase(i++);
} else {
++i;
}
}
}
这样这一端就可以算出下一次peer连接的时间,而对于另一端来说,他不知道此时要连接了,所以这个时候,应该要首先发起连接,当收到tracker服务器返回的peer列表的时候,对应的代码就是
//原本的逻辑,这个方法会执行peer的连接操作
addPeer(std::make_shared<Peer>(nodeInfo->getIpAddr(),nodeInfo->getPort()));
总结
总结下连接的时机:首先我们算出来的只是peer代表的主机下一次连接tracker的时间,注意是这个peer代表主机下一次连接tracker的时间,因为按我们的逻辑当这个peer收到了tracker返回的peer列表他首先会连接每一个peer,而对于另一端来说由于有计算peer下一次连接trakcer的时间,并把他放到了临时队列中,然后在checkPeerTimeToAdd 方法中检测当前临时队列是否有要连接的peer,判断的依据是根据当前的时间是否>=peer连接的时间,至于为什么要有小于 因为代码执行也是要时间的,所以小于的也要连接,这样俩者就同时发起连接了
举个列子:A先连接上tracker,紧接着B连接上tracker,而此时A不知道B连接上tracker,他只有等下一次tracker刷新的时间才能知道,当然这个可能对于B来说,此时他知道了A的连接时间,
他可以算出A下一次连接trakcer的时间,所以当A下次连接上tracker的时候,返回了B,连接B的时候,B此时也连接A,这样就通了,
当然这也只是理想的情况下,然而现实并不是这样的,有些网络会出现用户的端口号变化的情况,比如一开始A连接上trakcer,tracker服务器得知此时他的端口为9999,当到了下一次trakcer刷新的时候tracker服务器得到了端口为8888,这种情况下,A不知道B的端口号已经变了,他规划着下一次连接这个9999端口号的时间,当到了这个时间的时候,A发起连接9999的端口号,而此时这个9999的端口已经被别的应用程序占用了,导致连接不上,对于这种情况只能等他的端口号不变的时候才能连接上,要是一直变那就变成了对称型网络,那就无法打洞,在测试的阶段还发现了这样的网络,就是带有俩个ip的网络这样的也是非常无语的,还有就是运营商的拦截等,总之在国内这种网络情况,打洞能成功的概率还是比较低的。估计只有ipv6火起来的时候,p2p才是最火的时候
所以针对以上的,增加了手动打洞的功能,能更快速的更直接的知道是否能打洞
打洞的效果:
目前打洞的效果跟uTorrent 是一样的,他能打洞成功的,我们也可以实现打洞成功,他不行的我们也不行,虽然打洞不成功,但是还有本地发现,Dht等协议能协助互通的概率,本地发现已经介绍过,dht
后面会介绍



